Learn
Improving vector search over documents using HyDE
January 22, 2024 · 7 min read
The ability to efficiently search through documents and find relevant pieces of information is a crucial component of chatbots like Perplexity and search engines like Google. Vector databases are a powerful way to accomplish this. They store embeddings of documents and support efficient search for similar embeddings, which makes it easy to find similar documents to a query.
One method of improving the quality of results from vector search in these use cases is the Hypothetical Document Embeddings (HyDE) technique. In this article, we'll explain how HyDE works and walk through an example of how to use it to improve vector search.
How does HyDE improve vector search?
Finding the most relevant results possible is important for search, but can be difficult. For example, the text content on TikTok looks very different from the text content on Wikipedia, even if both documents are about the same topic. This can cause some mismatches even if both documents are about the same topic.
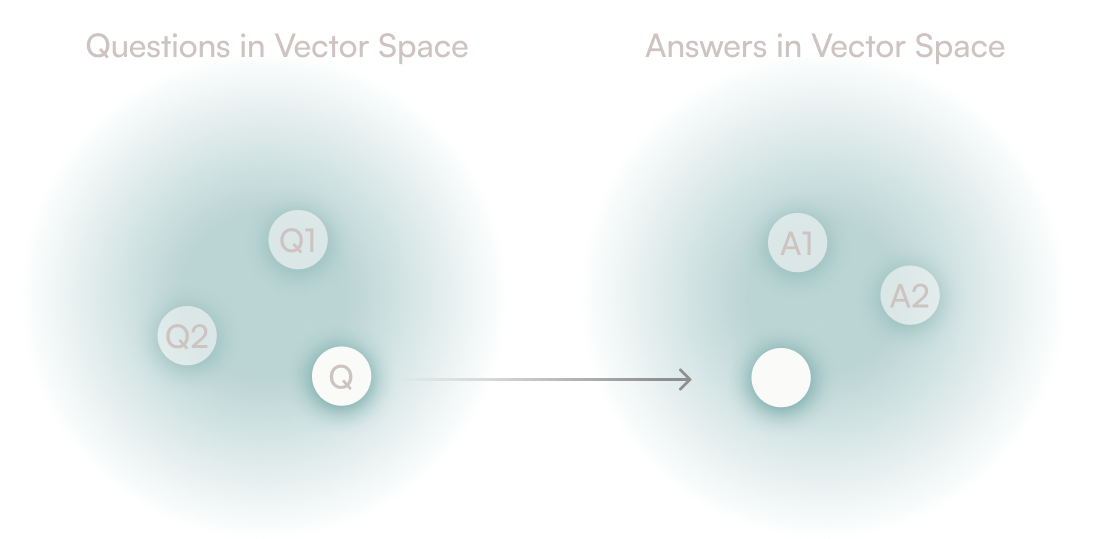
HyDE is a way to improve the quality of vector search. At a high level, it ensures that the structure of the query is similar to the structure of the documents in the database. This is important because the structure of the query is what vector search uses to find the most similar documents.
It works by using a large language model (LLM) like GPT-4 to generate a hypothetical document for a query. The hypothetical document may contain false details, but it will be more likely to have the same structure as a real document. We can then use vector search to find the most similar real document to the hypothetical document.
An application of HyDE to vector search
We'll create a question answering engine on insurance to test this out.
We'll give an overview here, but check the corresponding tutorial or our Jupyter notebook for additional details.
For our data, we’ll be using InsuranceCorpus. It's a dataset of 1000 pairs of questions and answers about insurance.
ID | Question | Answer |
|---|---|---|
0 | Is Disability Insurance Required By Law? | Not generally. There are five states that requ... |
1 | Can Creditors Take Life Insurance After... | If the person who passed away was the one with... |
2 | Does Travelers Insurance Have Renters Ins... | One of the insurance carriers I represent is T... |
Our goal is to be able to accept a question about insurance, and using our vector database, find the right answer.
We will set it up by storing the questions and answers in our database, and generating embeddings for each answer to perform vector search over. Then, whenever we get a question, instead of simply querying the database for answers that look similar to the query embedding, we'll use HyDE to improve the quality of our vector search:
- Ask an LLM (like ChatGPT) our question. It's okay if ChatGPT doesn't have a correct or up-to-date answer - we just need the structure in its answer to be similar.
- Take that (hallucinated) answer and generate an embedding for it.
- Use Lantern to perform a vector search, finding the nearest neighbors to the fake answer. Think of it as the "most similar" answer to our fake answer.
- Send the nearest-neighbor answer back as the answer. Since this is the closest approximation, it should have the correct answer.
You can imagine that the dataset might contain the most up-to-date answer to a question, but the LLM might have a better structure for the answer. This is why we use the LLM to generate a hypothetical answer, and then use vector search to find the most similar answer in the dataset.
How to get started with applying HyDE to vector search
Setup is simple thanks to our tools.
-
Set up a database with Lantern
With Lantern, we get a Postgres database and a vector database all-in-one. Postgres is a great way of storing different types of data for applications. Lantern adds vector search to Postgres, so we can store and search for vectors in the same database.
-
Create the table and insert data
We get the questions and the answers from the dataset; we'll compute the vector in the next step.
- id - The integer ID of the data
- question - The text content of the question
- answer - The corresponding text answer
- vector - The embedding for each answer
-
Generate embeddings for answers and add them to our database
You can use any method of your choice to generate embeddings for your data. Lantern makes embedding generation easy via our UI; just select the answer column and your embedding model, and Lantern will automatically populate the
vectorcolumn with embeddings. -
Construct an index for the vector column
After constructing the index, we'll be able to efficiently search for the nearest neighbors to a vector. From here, we’re ready to get started!
Evaluating vector search with HyDE
A quick recap of our strategy:
- Ask an LLM a question from the dataset
- Embed the LLM’s hallucinated answer
- Run a similarity search on that answer to find the closest (real) answer in the dataset
We show an example below.
Original Question:
How much does disability insurance cost?
Hallucinated Answer:
The cost of disability insurance varies widely depending on factors such as your age, health, occupation, coverage amount, and policy features. On average, it can range from 1% to 3% of your annual income. To get an accurate quote, you should contact insurance providers and request a personalized quote based on your specific circumstances.
Nearest-neighbor Answer:
Any disability insurance policy is priced based on several factors of the applicant. These include age, gender, occupation and duties of that occupation, tobacco use, and the amount of coverage needed or desired. The amount of coverage is often dictated by the person's earned income; the more someone earns, the more coverage that is available. There are several policy design features that can be included in the plan (or not) that will also affect the price. The person's medical history can also play an important role in pricing. As you can see, there are lots of moving parts to a disability policy that will affect the price. Doctors often buy coverage to protect their specific medical specialty.
Question associated in DB with nearest-neighbor answer:
How Much Is Disability Insurance For Doctors?
It worked! We found the real answer by getting the nearest-neighbor answer to the fake LLM answer. Notice also that the question associated with the nearest-neighbor answer is very similar to our original query question, which we would expect.
Conclusion
There you go - a quick walkthrough of how to use HyDE to improve vector search. The core principle is simple - use vector search to make the connection between the user question and what's in our database.
Thankfully, Lantern made this experiment easy. The easiest way to get started with Lantern is to sign up on Lantern Cloud. If you’d like help getting started, or advice on working with embeddings, we’re here to help. Please get in touch at support@lantern.dev.