Javascript Fullstack
WikiSearch - Search For Wikipedia Embeddings
In this article, we will go over how we built our wikisearch demo.
This demo performs a semantic similarity search between a query phrase that you type in and a large collection of text passages from Wikipedia articles. That is, you can search for the passages from Wikipedia that are the most relevant to any search query that you type in.
To power this kind of search application, we will need our text passages to be converted into vectors called embeddings, and then we will perform an approximate nearest-neighbor search over these embeddings. So, given an input search query, we turn that search query into its corresponding query vector/embedding, and then find the vectors/embeddings from our collection of passages that is closest to this query vector. We will then return the text passages associated with these closest vectors.
The first step would be to convert the massive collection of Wikipedia passages into embeddings, but luckily, Cohere has already done this. These embeddings have been pre-calculated by Cohere using their embed-multilingual-v2.0 model, which takes a piece of text and produces an embedding with 768 dimensions.
Hence, we will need to download these embeddings, store them in our Lantern database, and then use the same embedding model to get the embedding for our search query, and finally use Lantern's powerful vector search technology to retrieve the most relevant passages.
In this project, we use Lantern Cloud to host our vector-search enabled postgres database, and NextJS for our frontend and backend. We'll also use a script written in Python to aid in some one-time setup. If you wish to self-host an instance of Lantern, you can learn how to do so here.
Setup
Sign up for Lantern Cloud to create a database instance. In this demo, we assume that the instance you create has a user postgres, password postgres, and database ourdb.
Lantern Setup
Creating a Database
We'll first set up a database named "wikisearch" using Lantern Cloud. After this, we can copy a command from the Lantern dashboard to connect to our newly-created database. The command looks like this:
psql postgresql://username@netloc:port/dbnameThis command runs the psql postgres CLI tool, and passes along the connection URI (without the password) so that psql can connect to our cloud-hosted database. Once we run this command and enter the password we specified when we created our database, we are ready to create our table.
Let's create a new table with 9 columns:
CREATE TABLE passages (
id INT PRIMARY KEY,
title VARCHAR NOT NULL,
text_content TEXT NOT NULL,
url VARCHAR NOT NULL,
wiki_id INT NOT NULL,
views REAL,
paragraph_id INT NOT NULL,
langs INT NOT NULL,
emb REAL[]
);These are all the columns that Cohere's Wikipedia embeddings dataset contains.
Creating an Index
Now that we have a database with a table, let's create an index on our table. An index is a specialized data structure that will allow us to run queries on our data more efficiently. In particular, we need to create an index for our embeddings column so that Lantern can efficiently perform vector search on our embeddings.
We can easily create an index on our emb column from the Lantern dashboard. We will use the cosine distance as the distance metric, which is the specific method of computing distance between two vectors that this index will use. We also specify that the vectors in this column will have 768 dimensions, because that is how large the vector embeddings from the Cohere embedding model are.
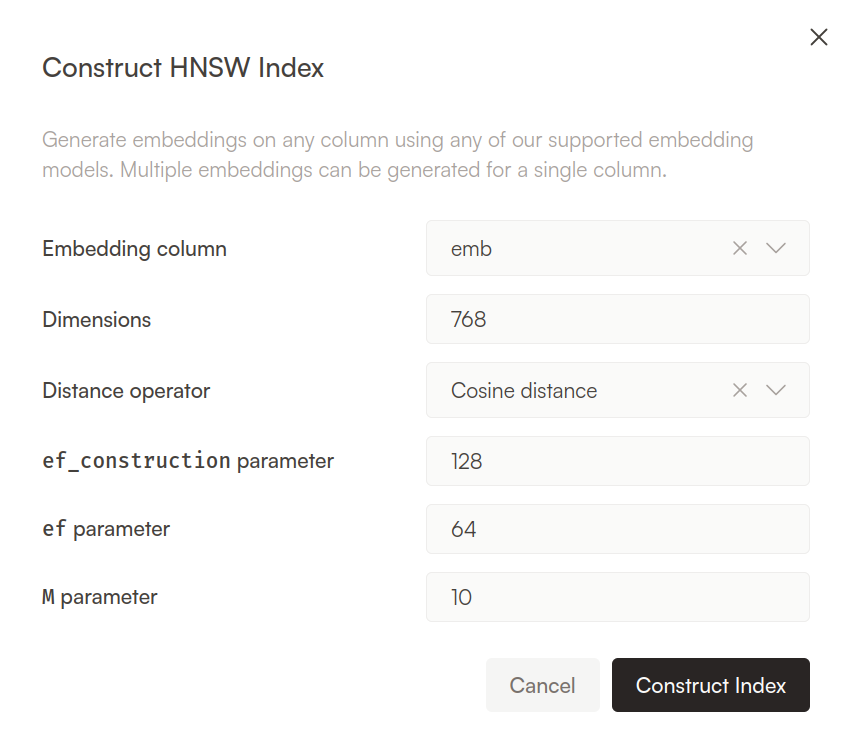
Note that we can also create the index after inserting rows into our passages, but we opted to create an index first because we plan to insert a lot of data (millions of rows). Hence, creating the index after we have inserted all of our data will require more processing and higher RAM on our database server (the RAM requirements for creating the index later might even be too high for your instance!). Generally, the decision as to whether to create an index before or after inserting data into your table depends on the specifics of your project, but creating one before inserting any data is almost always a good choice. Regardless, you only need to create the index once to start performing vector search on your data.
Inserting Data
Once we've created our table and index, we are ready to start inserting data into our database. Since the dataset containing our embeddings is hosted on Hugging Face, let's write a helper script in Python that downloads these embeddings from the dataset, and then inserts them into our Lantern database.
To connect to our cloud-hosted database, we will be using the psycopg2 library. Let's download it and also download the datasets library, which we will use to fetch the Wikipedia embeddings:
pip install datasets, psycopg2We'll then define our postgres connection URI. This URI is similar to the one we used to connect to psql, but we added the database password we specified when creating our database, so it'll have this structure: postgresql://username:password@netloc:port/dbname. However, make sure to keep this value private, as it contains sensitive database credentials! We store and retrieve them as environment variables here. We also specify the table that we've created earlier:
LANTERN_PG_URI = os.getenv("LANTERN_PG_URI")
TABLE_NAME = "passages"Let's connect to our database using the psycopg2 library next:
conn = psycopg2.connect(LANTERN_PG_URI)
print("Connected to Lantern database!")Next, we'll fetch the data which contains the embeddings that Cohere has prepared and computed. We use the datasets library to fetch this data from Hugging Face. We specify the streaming parameter to download chunks of this data at a time instead of downloading it all at once, because the entire dataset is quite large.
from datasets import load_dataset
entire_dataset = load_dataset("Cohere/wikipedia-22-12-en-embeddings", split="train", streaming=True)Let's now define a function called batch_insert which takes a list of samples from this dataset and inserts it into our postgres database. We choose to do this in batches to speed things up.
def batch_insert(rows):
start = time.time()
data = [(row['id'], row['title'], row['text'], row['url'], row['wiki_id'], row['views'], row['paragraph_id'], row['langs'], row['emb']) for row in rows]
cur = conn.cursor()
query = f"INSERT INTO {TABLE_NAME} (id, title, text_content, url, wiki_id, views, paragraph_id, langs, emb) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)"
cur.executemany(query, data)
conn.commit()
cur.close()
elapsed = time.time() - start
return elapsedCohere suggests using the dot product similarity with these embeddings. Since our index is configured to use cosine distance (the distance analogue of cosine similarity), we can make these two methods equivalent by normalizing our vectors to have a magnitude of 1. We write a function that does this with numpy, by computing the length of the vector and then dividing each element by this length:
import numpy as np
def normalize_vector(v):
v = np.array(v)
magnitude = np.linalg.norm(v)
return (v / magnitude).tolist()Now we're ready to let the script run and upload data into our database. Here, we upload 1 million rows in batches of size 1,000:
num_rows = 1_000_000
batch_size = 1_000
batch = []
batch_n = 1
batch_start = time.time()
for i, row in enumerate(entire_dataset):
if (i+1) > num_rows:
break
row['emb'] = normalize_vector(row['emb'])
batch.append(row)
if len(batch) == batch_size:
batch_end = time.time()
print(f"Batch# {batch_n} took {batch_end - batch_start}s to download")
print("Inserting batch...")
elapsed = batch_insert(batch)
print(f"Finished inserting batch! Took {elapsed}s")
batch = []
batch_n += 1
batch_start = time.time()After letting this script run, we can verify that all our rows have successfully been inserted by running a query inside psql:
SELECT COUNT(*) FROM passages;which will tell us the number of rows that we now have in our passages table.
Backend
Now that our database has data in it, let's start building the backend for our search app. We'll create a NextJS api route called /search.
After setting up a NextJS project, we'll first install the pg package which will allow us to connect to postgres:
npm install pgWe'll create a file called db.js and place it inside a utils folder, which will be responsible for connecting to our database once, and then exporting a function DBQuery that allows us to run queries on our database. Here, LANTERN_DB_PG_URI is the same sensitive URI (with our database password!) that we used in our Python script above.
// db.js
import { Pool } from "pg";
const pool = new Pool({
connectionString: process.env.LANTERN_DB_PG_URI,
});
export const DBQuery = (text, params) => pool.query(text, params);Behind the scenes, the pool manages a collection of database connections. Note that you should manage this pool of database connections in a way that makes the most sense for your project. For the purposes of this demo, this will default approach will suffice.
Now, let's start implementing search.js for our /search endpoint. We'll first import the DBQuery function we just wrote:
import { DBQuery } from "@/utils/db";Next, we will write a function to normalize the embeddings we receive from Cohere after retrieving embeddings for our search queries. We do this for the same reason that we do in the insertion script: by normalizing, using the cosine distance effectively becomes equivalent to using dot product similarity.
function normalizeVector(vector) {
let magnitude = Math.sqrt(vector.reduce((sum, val) => sum + val * val, 0));
return vector.map((val) => val / magnitude);
}Now we'll write the function to handle the request to the endpoint:
export default async function handler(req, res) {
if (req.method === "POST") {
const { query } = req.body; // the search query
// ...
// rest of our code below
// ...
} else {
// Handle any other HTTP methods
res.setHeader("Allow", ["POST"]);
res.status(405).end(`Method ${req.method} Not Allowed`);
}The first thing we will do when processing a request with a search query is embed the search query using Cohere. We do this by calling their API, and using our Cohere API key in the environment variable COHERE_API_KEY. Note that, as mentioned previously, we use the embed-multilingual-v2.0 model:
// Get the embedding from cohere
try {
const response = await fetch("https://api.cohere.ai/v1/embed", {
method: "POST",
headers: {
accept: "application/json",
authorization: `Bearer ${process.env.COHERE_API_KEY}`,
"content-type": "application/json",
},
body: JSON.stringify({
texts: [query],
truncate: "END",
model: "embed-multilingual-v2.0",
}),
});
if (!response.ok) {
throw new Error(`Error: ${response.status}`);
}
const data = await response.json();
// Check if the 'embeddings' field is present in the response
if (data && data.embeddings) {
var embedding_vector = data.embeddings[0];
embedding_vector = normalizeVector(embedding_vector);
} else {
throw new Error("Embeddings field not found in the response");
}
} catch (error) {
console.error("Cohere API call failed:", error);
res.status(500).json({
error: "Failed to fetch data from Cohere, or embeddings missing",
});
return;
}Note that we normalized the embedding we receive from Cohere above.
Now that we have our embedding, all that remains is to run vector search with our database. First, we have to set the enable_seqscan variable to false:
SET enable_seqscan = false;This will force postgres to use the index we created previously during queries on our embedding column. Since this is a session variable, and we are not directly managing our database connections in the connection pool, we should run this before every search query.
The query that performs the actual vector search looks like this:
SELECT title, text_content, url, cos_dist(emb, ARRAY[0.212, 0.12, ... this is our embedding vector...]) FROM passages ORDER BY emb <=> ARRAY[0.212, 0.12, ... this is our embedding vector...] LIMIT 10;where ARRAY[0.212, 0.12, ... this is our embedding vector...] is our target vector (the vector against which we are computing distances to from all other vectors in our database).
The first part of this query specifies the columns we want to retrieve. In our case, we want to get the title, content of the text passage, the URL of the original article, as well as the actual cosine distance of our top candidates.
This second part of this query, after the ORDER BY clause, performs the actual search. The <=> operator triggers postgres to use Lantern's index to perform vector search according to the cosine distance metric (the same one we specified during creation of our index) to find the (approximate) closest neighbors to the specified vector-- that is, the vectors with the smallest distance to our target vector.
Why do we use the <=> operator? Because this operator corresponds to the cosine distance (see docs here). Since we created our index and specified it to use the cosine distance, using the corresponding operator <=> will end up using our index, which will perform the vector search efficiently. If we were to use another operator, such as <-> which corresponds to squared Euclidean distance, then our vector search won't use our index (since our index was constructed with the cosine distance specified) and our search will be very inefficient. Unless, of course, we construct another index that uses the squared Euclidean distance.
Lastly, we only want the top 10 passages to show in our search results, so we include LIMIT 10 at the end of the query. Note that the session setting init_k optimizes our index to more efficiently return a specific amount of nearest neighbors. So, if we instead wanted to return the top 25 results, we could run this query prior:
SET hnsw.init_k = 25;and our index will be optimized to return 25 neighbors instead.
Putting the above together, this is what the entire search process looks like:
// Perform vector search with Lantern
const TABLE_NAME = "passages";
await DBQuery("SET enable_seqscan = false;");
// Get vector as a string that we can put inside our serach query
const embedding_vector_str = `[${embedding_vector.join(",")}]`;
try {
const search_query = `SELECT title, text_content, url, cos_dist(emb, ARRAY${embedding_vector_str}) FROM ${TABLE_NAME} ORDER BY emb <=> ARRAY${embedding_vector_str} LIMIT 10;`;
var { rows } = await DBQuery(search_query);
} catch (error) {
console.error("Database query error:", error);
res.status(500).json({ error: "Internal server error" });
}
// Return results
res.status(200).json({
message: "Search successful",
query,
results: rows,
});Frontend
After setting up a basic UI of our app in NextJS with TailwindCSS (you can check out the full github repo below) as well as a search bar that invokes our /search endpoint and stores the results in a state variable called searchResults, we'll create a component to show our search results:
const SearchResult = ({ title, text, link, distance, bg_color }) => {
return (
<div className={`${bg_color} rounded`}>
<div className={`py-4 pl-3 lg:py-4`}>
<div className="flex justify-between">
<h2 className="mb-3 text-lg font-bold lg:text-2xl lg:font-extrabold tracking-tight text-gray-900">
{title}
</h2>
<div>
<span className="bg-blue-100 text-blue-800 text-xs font-medium me-2 px-2.5 py-0.5 rounded">
{`Distance: ${distance.toFixed(3)}`}
</span>
</div>
</div>
<p className="mb-3 text-gray-500">{text}</p>
<a
href={link}
className="inline-flex items-center font-medium text-blue-600 hover:text-blue-800"
>
Read Full Article
<svg
className="w-2.5 h-2.5 ms-2 rtl:rotate-180"
aria-hidden="true"
xmlns="http://www.w3.org/2000/svg"
fill="none"
viewBox="0 0 6 10"
>
<path
stroke="currentColor"
strokeLinecap="round"
strokeLinejoin="round"
strokeWidth="2"
d="m1 9 4-4-4-4"
/>
</svg>
</a>
</div>
</div>
);
};Finally, we can render our search results using the component we just made:
{
searchResults.length > 0 && (
<div className="w-full mt-6">
<div className="flex justify-between">
<p className="text-md text-gray-400">Results</p>
</div>
<hr className="mb-2 h-0.5 border-t-0 bg-neutral-100 opacity-100" />
{searchResults.map((item, idx) => (
<SearchResult
title={item.title}
text={item.text_content}
link={item.url}
distance={item.cos_dist}
bg_color={idx % 2 == 0 ? "bg-white" : "bg-gray-50"}
/>
))}
</div>
);
}Example
Let's run the search query "how many devices has apple sold" and see what kind of results we get:
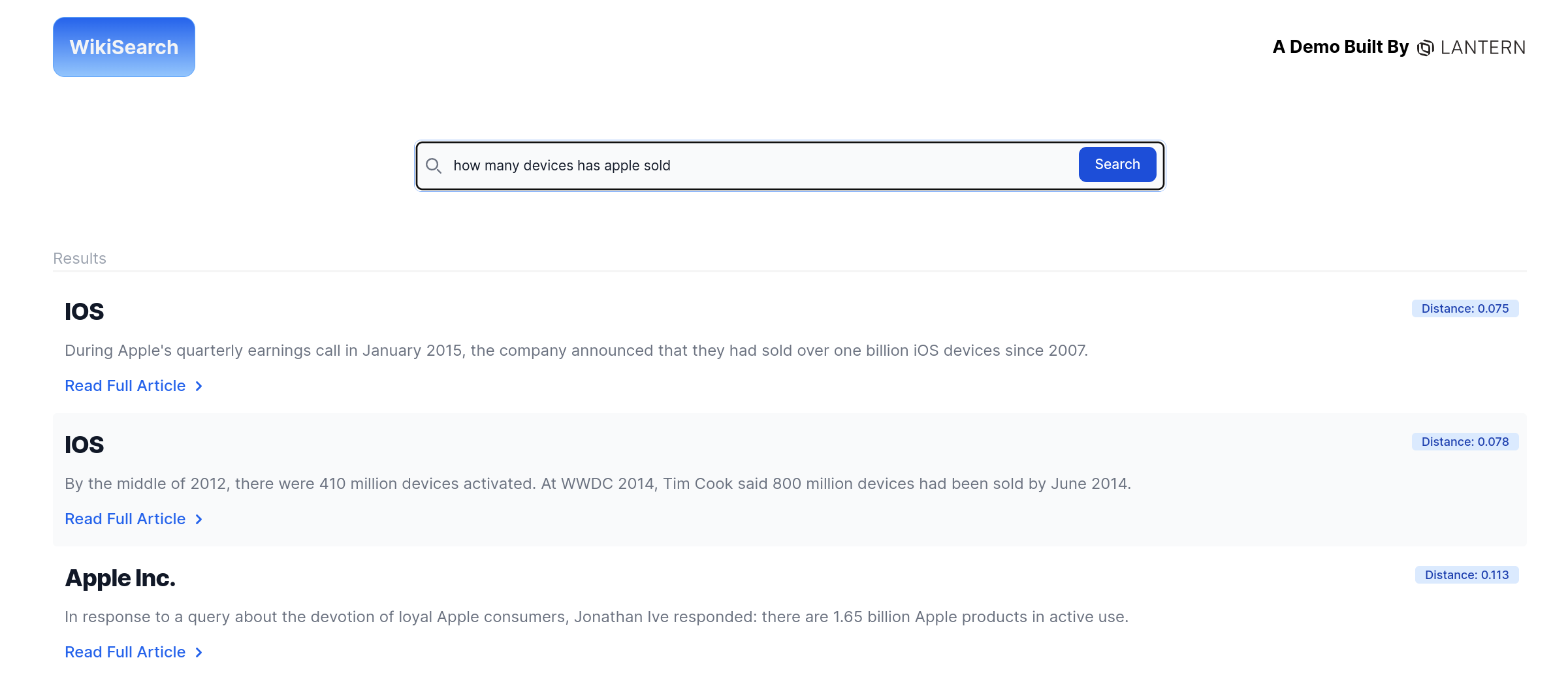
As we can see, the passages returned are highly relevant to the search query. We can also see what the distance of each passage is, with the lowest distances (the perceived "most relevant" passages) being located at the top.
Thanks for reading along how we built this demo! We look forward to seeing what you build next with Lantern.
The full code for this project can be found on github.