OpenAI released two new embedding models in January 2024, and they're a big improvement. Both models - a small, efficient model and a large, powerful one - offer significantly stronger performance.
In terms of metrics:
-
text-embedding-3-small -
text-embedding-3-large- MIRACL average score increase from 31.4% to 54.9%
- MTEB average score increase from 61.0% to 64.6%
Does a raw metric increase automatically mean better performance for your use case?
Not necessarily.
To show this, we'll take a look at an experiment we ran in collaboration with Parea AI. We'll use Lantern, a Postgres vector database and toolkit, to set up and manage our vectors. It's faster than pgvector, and cheaper than Pinecone. To actually run the experiment, we'll use Parea's SDK for debugging, evaluating & monitoring LLM apps. Their built-in testing feature is perfect for what we’ll measure.
We'll compare a few different embedding models in their performance retrieving data for a given task. We'll show how different results can be, even for the world's most advanced embedding models.
If you're curious, here's the Github repo with our code and analysis, and a link to the experiments on Parea.
Let's start with an overview of our experiment.
Building the right test for the embedding models
The dataset
We’ll be using the Asclepius Clinical Notes dataset of synthetic physician summaries from clinical settings. Paired with those settings are questions about the summary and answers to those questions.
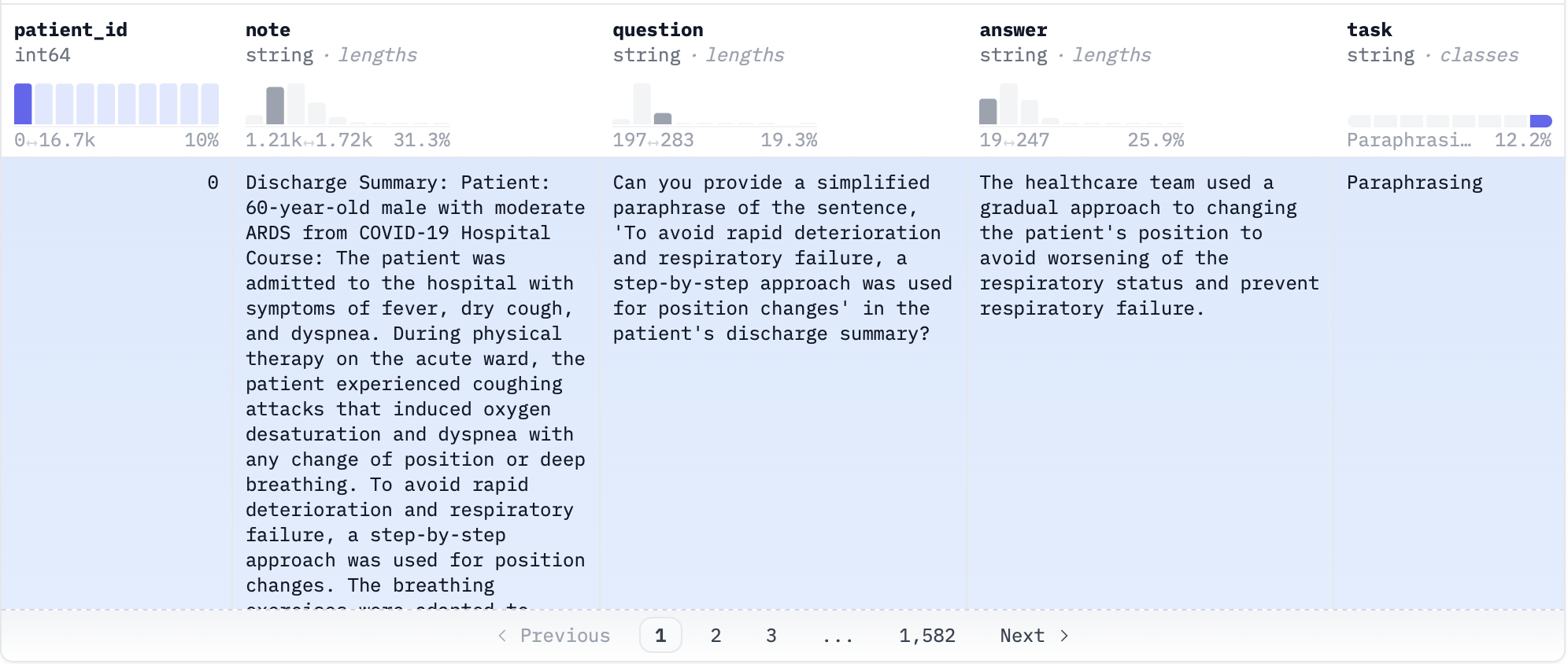
Each data point has the following parts:
- A note about the medical situation
- A question about the medical situation. An example might be "Based on the note, what treatment plan did the doctor prescribe for x"
- The answer to that question
- A task categorization to indicate what the question is asking (e.g. provide a simplified paraphrase (Paraphrasing) vs answer a question about the note (Q&A)).
The Q&A task subset has 20,038 samples, and the Paraphrasing task subset has 19,255 samples.
This dataset is helpful for two reasons.
First, since the data is synthetic and clinical, it’s unlikely to appear in the training dataset for the embedding models.
Second, measuring the performance of the embedding model on the Paraphrasing subset means to assess how well the embedding model clusters texts which express the same content. Measuring the performance on the Q&A subset means to assess how well the embedding model clusters related texts/content together. The latter assessment is predictive for situations where one uses the embedding model to retrieve FAQs to power a chatbot.
The embedding models
To compare performance against OpenAI’s new embedding models, we’ll need strong contenders.
We’ll use OpenAI’s previous generation models, and BAAI’s bge-base-en-v1.5.
From OpenAI, we’ll test OpenAI’s new embedding models, and their old ones. Namely:
text-embedding-ada-002- embedding dimension of 1536- This is OpenAI’s previous model, released in December 2022
text-embedding-3-small- with embedding dimensions 512 and 1536- More powerful and 80% cheaper than the previous generation
text-embedding-3-large- with embedding dimensions 256 and 3072- More powerful and 30% more expensive(!)
Recall that we use embedding models to represent data as vectors, where similar vectors have a smaller distance from each other.
We may want a lower dimension vector to reduce memory usage. Open AI’s latest embedding model uses a new technique called Matroyshka Representation Learning, or MRL, which allows for an easy way of obtaining a compressed vector representation if desired — just get a subset of the vector.
Designing our test
The tests are straightforward. Each data point is a clinician’s note, a question about that note, an answer, and the task category. We will benchmark each embedding model to retrieve the correct answer out of all answers for the task subset given a question. For that we will follow these steps:
- Use Lantern to embed each data entry of the task subset with the respective embedding model, in two parts
- Embed the question as a vector
- Embed the answer as a vector
- Use Parea’s SDK to execute the experiment, i.e. perform the following steps:
- Define a function that, given a question and task category, searches the answer column of the task subset for the top-20 approximate nearest neighbors (ANNs) using the vector representation of that question (code).
- Define evaluation metrics which calculate
- Hit rate @ 20 - Measures if the correct answer appears in the top 20 at all. This is a binary yes/no result. Higher average is better (code).
- Mean Reciprocal Rank (MRR) - Measures how close the correct answer is to the first rank. For example, if the correct answer ranks 1 by the model, the MRR is 1/1 or 1. If the correct answer ranks 4, the correct answer is ¼ or 0.25. High value is better as it means a lower rank (code).
- Create and run the experiment which takes the above function and applies it over the dataset (code).
The Results
TL;DR - Top-tier benchmarks don’t guarantee better performance in real-world tasks. OpenAI’s smaller model still performs just as well at a fraction of the cost. Don’t count out open-source, either; BGE’s base embedding model shows similar quality.
Q&A Task
Embedding Model | Embedding Dimension | MRR @ 20 | Hit Rate @ 20 |
|---|---|---|---|
| 768 | 0.70 | 0.81 |
| 1536 | 0.69 | 0.81 |
| 512 | 0.73 | 0.84 |
| 1536 | 0.73 | 0.84 |
| 256 | 0.68 | 0.82 |
| 3072 | 0.73 | 0.85 |
Paraphrasing Task
Embedding Model | Embedding Dimension | MRR @ 20 | Hit Rate @ 20 |
|---|---|---|---|
| 768 | 0.37 | 0.50 |
| 1536 | 0.44 | 0.57 |
| 512 | 0.46 | 0.59 |
| 1536 | 0.46 | 0.59 |
| 256 | 0.44 | 0.61 |
| 3072 | 0.48 | 0.64 |
Summary
OpenAI’s new embedding models perform better on some common metrics. But benchmarks and dimensions aren’t everything. Aligning your embedding model with your use case and data will pay off, so don’t just pick the newest or most expensive.
Choose your embedding models carefully, and evaluate your performance frequently.
Parea + Lantern is a fast and easy way to get started with AI applications. Lantern lets you build a vector database from your Postgres database with ease and generate embeddings even easier - just pick a column and a model. With Parea’s toolkit, you’ll spend less time debugging and integrating your LLM application. Their all-in-one platform lets you debug, test, evaluate, and monitor every stage.
In our second article, we build a reference-free evaluation of our retrieval setup. This is useful as one typically doesn’t have access to the “correct” answer in a production environment.