📌 TL;DR
Lantern is a PostgreSQL vector database extension for building AI applications. Install and use our extension here.
🚀 Features today + Coming soon
We have the most complete feature set of all the PostgreSQL vector database extensions.
Here’s what we support today:
- Creating an AI application end to end without leaving your database (example)
- Embedding generation for popular use cases (CLIP model, Hugging Face models, custom model)
- Interoperability with
pgvector's data type, so anyone usingpgvectorcan switch to Lantern - Parallel index creation capabilities -- Support for creating the index outside of the database and inside another instance allows you to create an index without interrupting database workflows.
Here’s what’s coming soon:
- Cloud-hosted version of Lantern
- Templates and guides for building applications for different industries
- Tools for generating embeddings (support for third party model API's, more local models)
- Support for version control and A/B test embeddings
- Autotuned index type that will choose appropriate index creation parameters
- 1 byte and 2 byte vector elements, and up to 8000 dimensional vectors support
- Request a feature at [email protected]
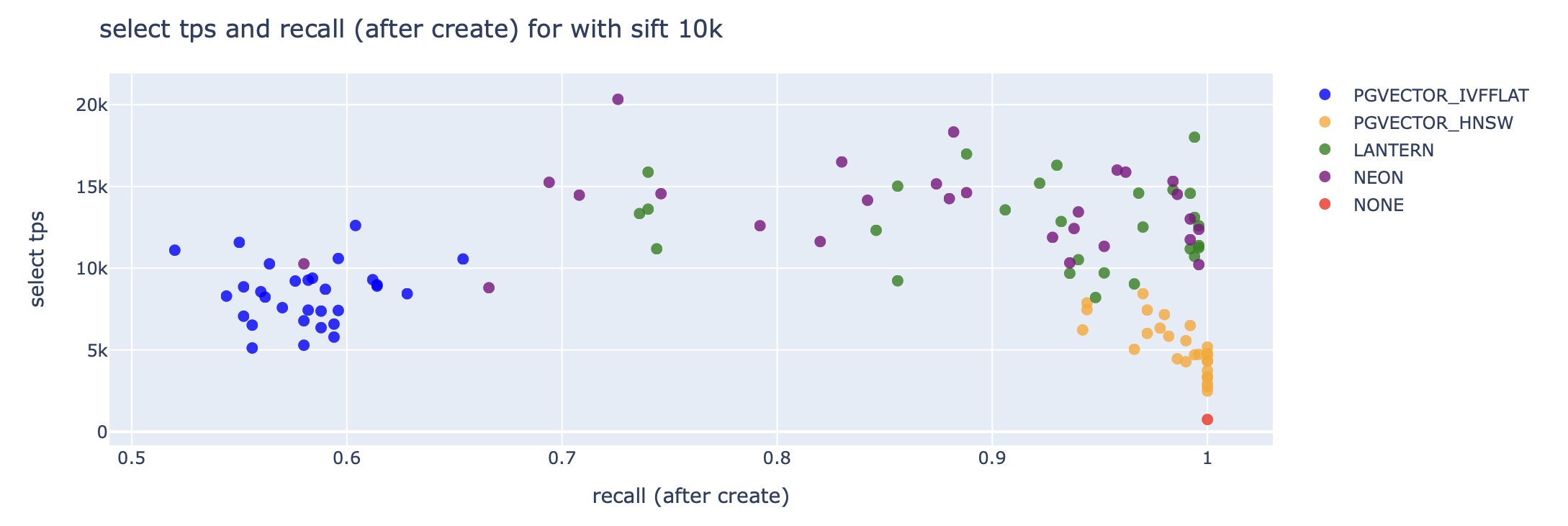
📈 Performance + Benchmarks
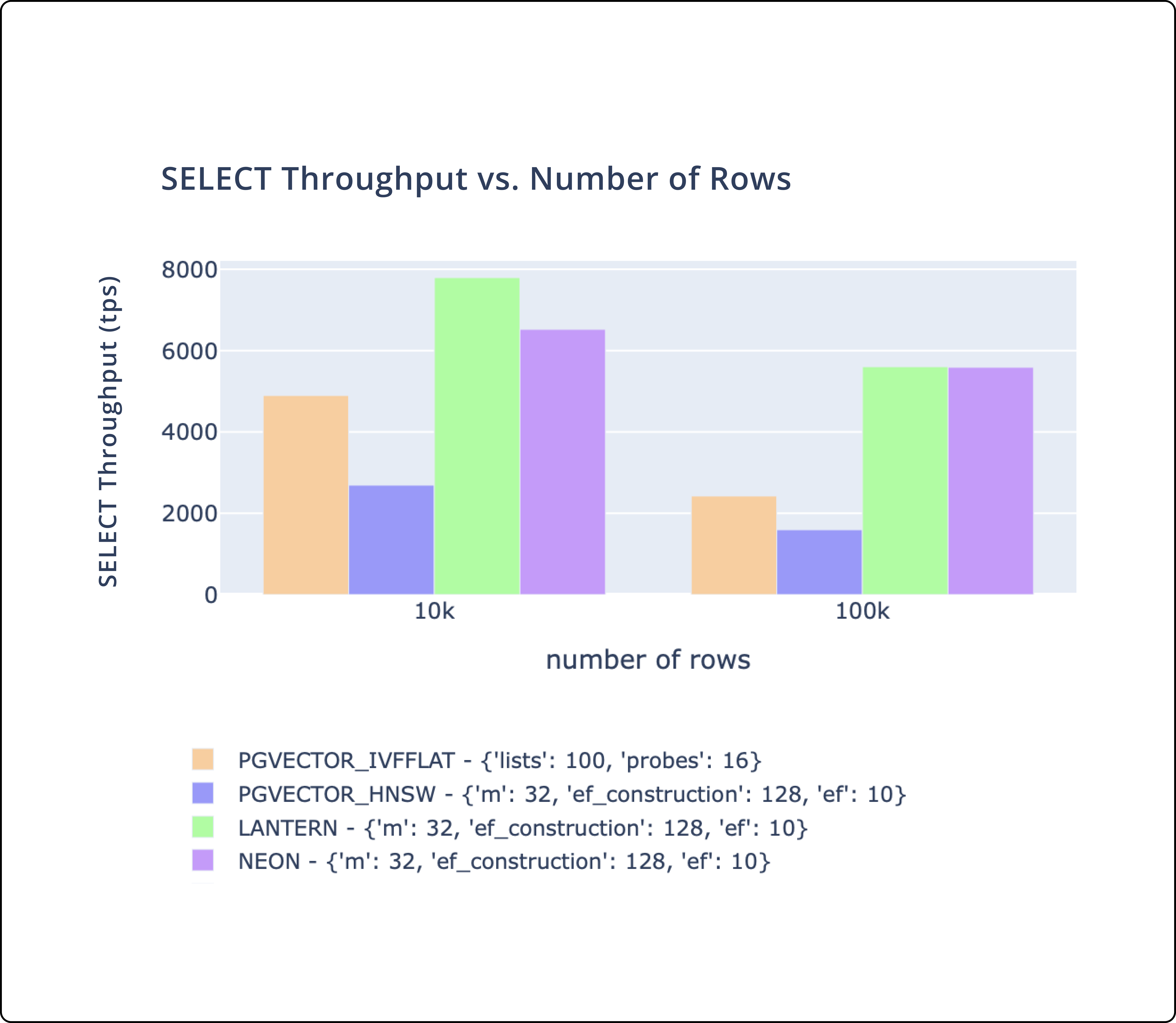
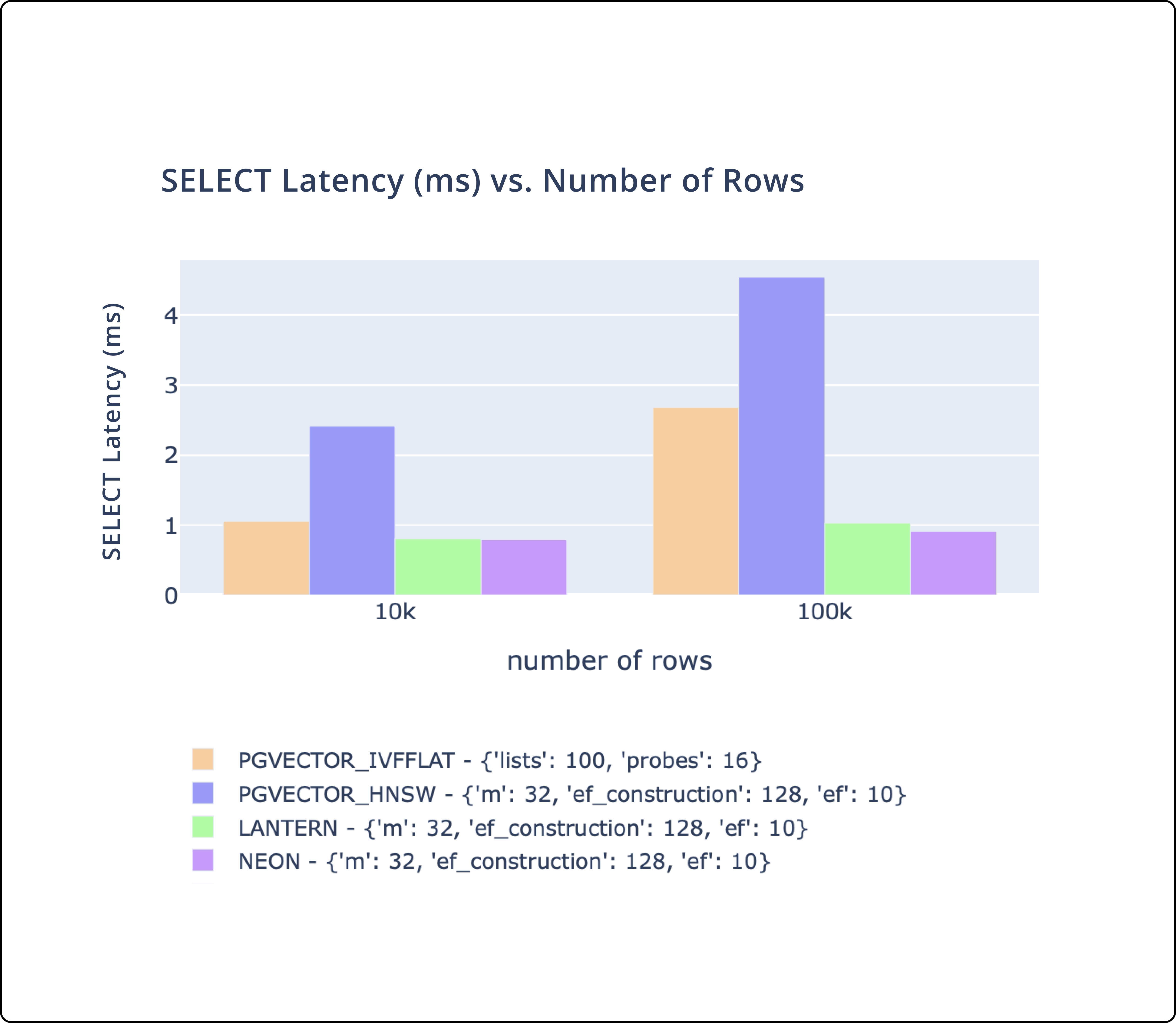
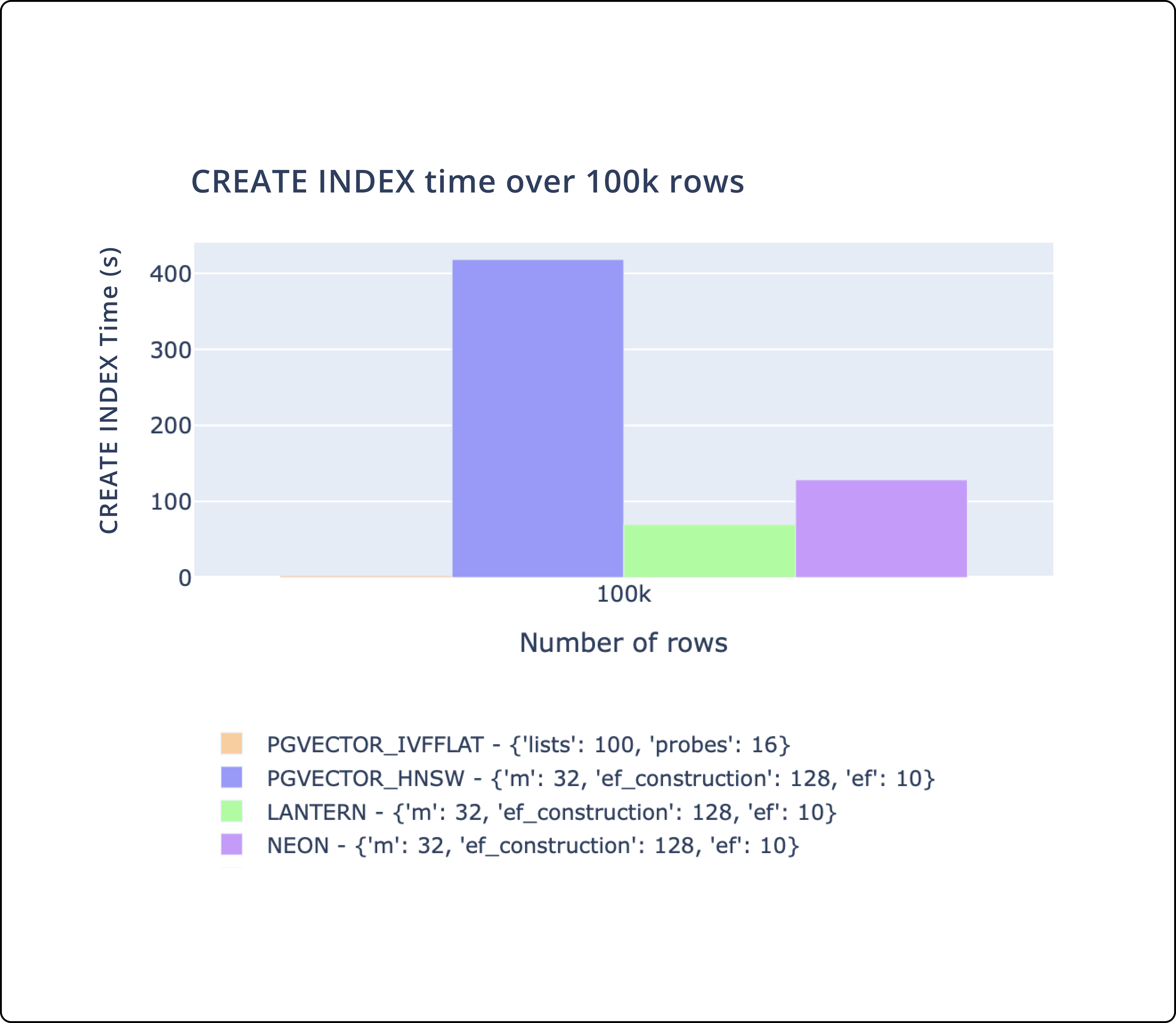
Lantern is a PostgreSQL extension that creates an index to efficiently search for similar vectors.
Important takeaways:
- There's three key metrics we track.
CREATE INDEXtime,SELECTthroughput, andSELECTlatency. - We match or outperform
pgvectorandpg_embedding(Neon) on all of these metrics. - We plan to continue to make performance improvements to ensure we are the best performing database.
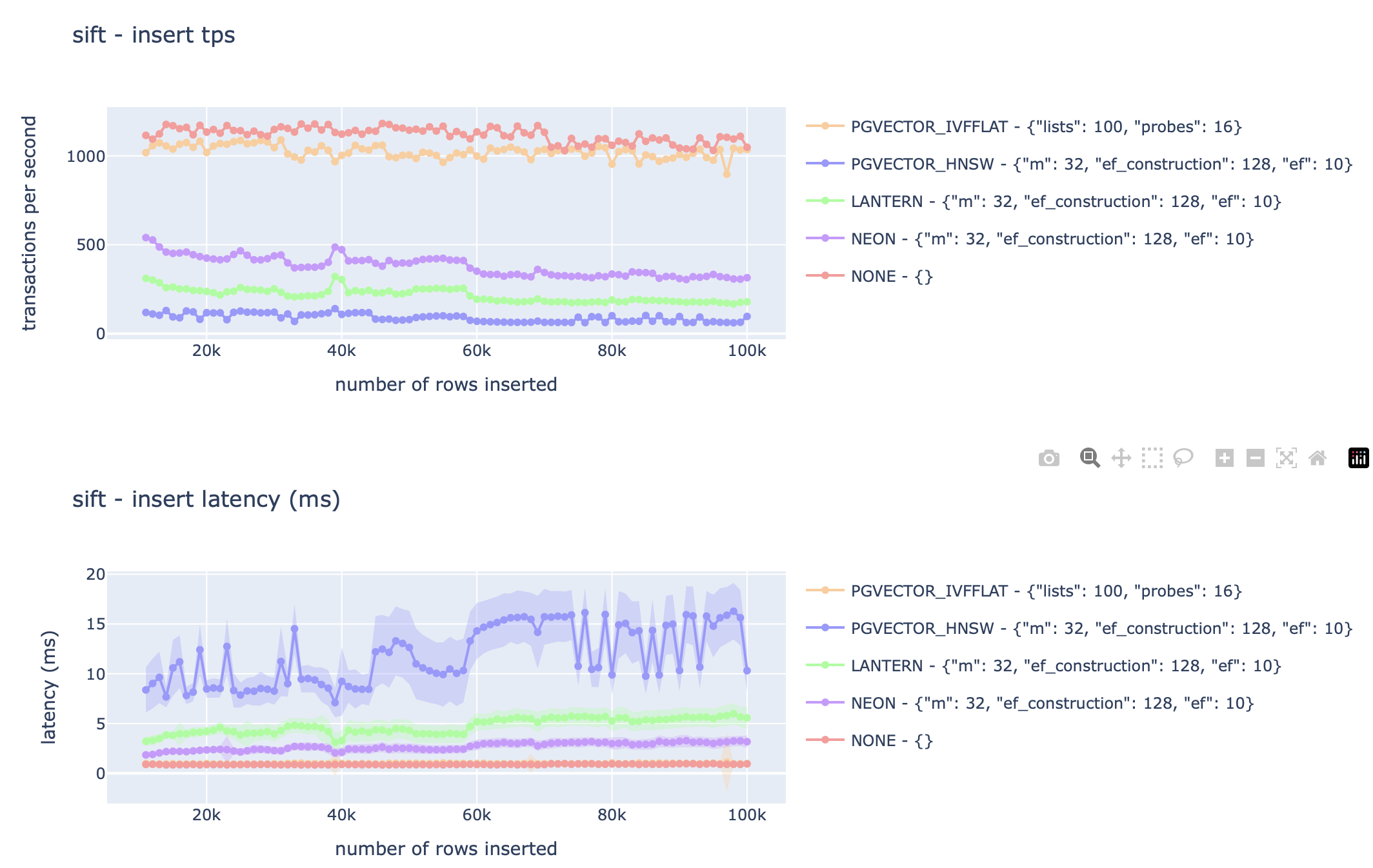
For those curious, we also generated charts for insertion latency and throughput and recall vs. throughput.
{kind=link}
{kind=link}
Our database is built on top of usearch — a state of the art implementation of HNSW, the most scalable and performant algorithm for handling vector search.
🌱 Why we started Lantern
Today, there's dozens of vector databases on the market, but only TWO are built on top of PostgreSQL.
We think it's super important to build on top of PostgreSQL
- Developers know how to use PostgreSQL.
- Companies already store their data on PostgreSQL.
- Standalone vector databases have to rebuild all of what PostgreSQL has built for the past 30-years, including all of the optimizations on how to best store and access data.
Lantern is building the most performant vector database and the best suite of tools to help developers build AI applications.
We want to help companies build useful applications using their unstructured and structured data.
🎁 Asks + Offers (FREE AirPods + advice)
Send us feedback + report bugs
- Please try our extension! We expect some bugs in production, since we’re new, but we promise to patch them very quickly
Switch from pgvector, get FREE AirPods Pro
- If you’re already using
pgvectorin production for your business, switching to Lantern is very easy - Book some time here, and we will help switch you over for FREE and get you a pair of FREE AirPods Pro
Want to build AI applications and don’t know where to start?
- Book some time here, we will meet for FREE and help you get set up on Lantern
Want to contribute or join the team?
- Reach out to [email protected], we can find an open issue or project that suits you
- We are also hiring full time engineers. Send your resume to [email protected]!