What are vectors?
Vectors are arrays of numbers. In AI applications, vectors generally represent data like images or text in high-dimensional space for efficient computation. There are two types of vectors:
- Dense vectors: These are vectors where most elements are non-zero, effectively capturing semantic information.
- Sparse vectors: These are vectors where most elements are zero. They are efficient for tasks requiring keyword matching and handle rare terms well.
In most AI contexts, the term 'vector' typically refers to a dense vector unless otherwise specified.
How are vectors used?
Vectors are particularly useful for retrieval-augmented generation (RAG), a technique used by many AI applications. RAG involves embedding a large collection of documents and storing these embeddings in a vector database. At query time, the application can embed the query and search for the most relevant documents based on the similarity between the query and the document embeddings.
These retrieved documents are then provided as context to a large language model (LLM) to complete the task. This process helps ensure the information provided by the LLM is accurate, up-to-date, and includes proprietary or specialized knowledge.
What are dense vectors?
Dense vectors are high-dimensional vectors produced by embedding models, such as Open AI’s text-embedding-3-large, which has 3074 dimensions.
Dense vectors are particularly useful for semantic search, which retrieves documents based on the meaning of the query rather than just matching words. This contrasts with lexical search, which simply looks for documents with matching words. For example, dense vectors can capture the relationship between words like "king" and "queen", which are related concepts but not synonyms.
Lantern, a hosted Postgres service, supports both one-off and automatic embedding generation inside Postgres. For one-off embedding generation in SQL, you can use the following command:
SELECT openai_embedding('openai/text-embedding-ada-002', 'King');For automatic embedding generation, Lantern will generate embeddings for your data as you insert new rows. You can enable automatic embedding generation inside the Lantern dashboard.
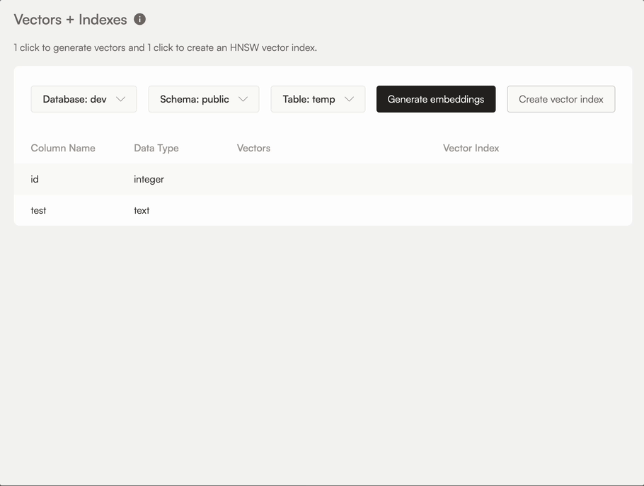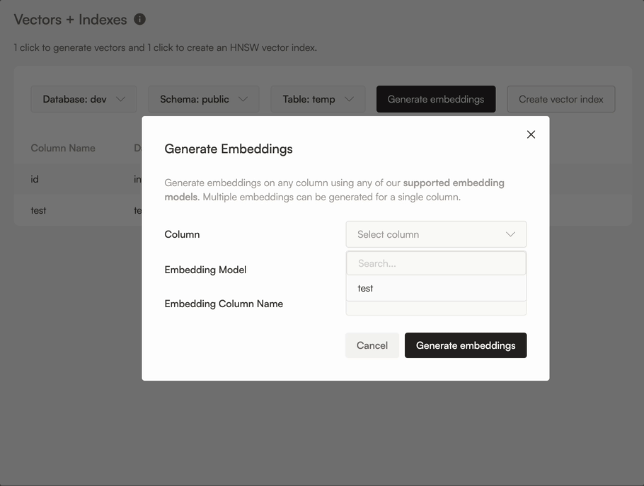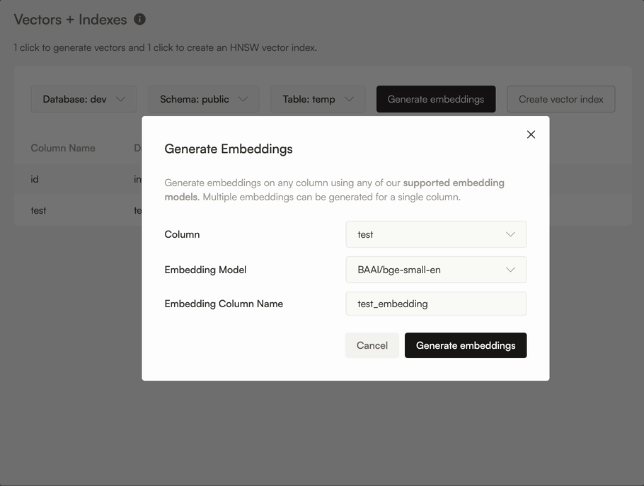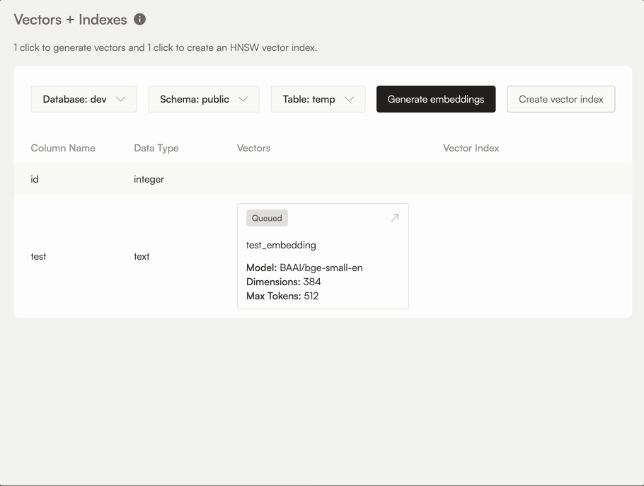
Alternatively, you can also create and manage a vector column yourself:
CREATE TABLE items (id bigserial PRIMARY KEY, dense_vector REAL[3074]);To enable efficient search over the column, you can create an index over the vector column with Lantern:
CREATE INDEX ON items USING lantern_hnsw (dense_vector dist_l2sq_ops);Finally, you can also query the for nearest vectors:
SELECT * FROM items ORDER BY dense_vector <-> openai_embedding('openai/text-embedding-ada-002', 'Elizabeth II'); LIMIT 5;For more information on embedding generation, you can refer to the Lantern documentation here and here
What are sparse vectors?
Sparse vectors are high-dimensional vectors where most of the values are zero. When sparse vectors are used to represent text, the dimensions typically correspond to individual words. This results in vectors with many zeros and a few non-zero values. This sparsity makes them efficient and effective for tasks involving keyword matching, providing interpretable results, and handling rare terms well. This contrasts with dense vectors, which are more suited for semantic understanding.
One technique for generating sparse vectors is SPLADE (Sparse Lexical and Expansion Model). SPLADE uses language models to generate sparse vectors that account for the semantic similarity of words, handling synonyms, misspellings, lemmatization, and stemming. This approach contrasts with traditional methods that rely solely on word frequency.
Sparse vectors are often higher-dimensional than dense vectors. For example, the latest SPLADE model naver/splade-v3 produces 30522-dimensional vectors, but very few of these dimensions will be non-zero.
In contrast to dense vectors, sparse vectors are often stored as mappings of indices to numbers. This is more efficient since most of the dimensions are zero. This conversion is handled by the Postgres extension pgvector with the data type sparsevec. The sparse vectors can be indexed to achieve efficient search, as seen below.
Lantern’s hosted Postgres service supports sparse embedding generation. For one-off embedding generation in SQL, you can use the following command:
SELECT text_embedding('naver/splade-v3', 'King');Lantern’s hosted Postgres service uses pgvector to support storage and retrieval. To create a table with 30522-dimensional sparse vectors:
CREATE TABLE items (id bigserial PRIMARY KEY, sparse_vector sparsevec(30522));Index creation retains the same API. To search for nearest vectors:
SELECT * FROM items ORDER BY sparse_vector <-> text_embedding('naver/splade-v3', 'Queen') LIMIT 5;What is hybrid vector search?
Hybrid vector search combines the strengths of both sparse vector search and dense vector search. By combining exact term matching with semantic understanding, hybrid vector search improves accuracy relative to using sparse vector search or dense vector search alone. This approach is particularly beneficial for complex and large-scale datasets.
Hybrid vector search involves generating sparse embeddings and dense embeddings over the same corpus. When processing a search query, a sparse vector is generated to query the sparse vector index for nearest neighbors, and a dense vector is generated to query the dense vector index for nearest neighbors. The nearest rows from both vector types are then combined, and the final nearest neighbors are determined by calculating a weighted score over this subset.
The weights can be adjusted based on the embedding models and the data distribution to optimize performance.
To search for nearest vectors using hybrid vector search:
SELECT * FROM lantern.weighted_vector_search(
CAST(NULL AS items),
w1 => 0.8,
col1 => 'dense_vector',
vec1 => openai_embedding('openai/text-embedding-ada-002', 'Elizabeth II'),
w2 => 0.2,
col2 => 'sparse_vector',
vec2 => text_embedding('naver/splade-v3', 'Queen')
)Full documentation on hybrid vector search can be found here.
Experiment
BEIR Framework
To evaluate the performance of hybrid vector search, we conducted an experiment using the BEIR (Benchmarking Efficient Information Retrieval) framework. BEIR is a comprehensive benchmark for zero-shot evaluation of information retrieval models, covering 18 datasets across various information retrieval tasks.
We used the following datasets:
- Scifact
- Scidocs
- FiQA*
- Quora
- NQ*
Of these, FiQA and NQ are specifically intended for the question-answer retrieval task. The others span various retrieval tasks, including citation and question-question retrieval.
Configuration
As a baseline retrieval model, we used Elasticsearch with default parameters. Elasticsearch is a popular search engine known for its robust performance and advanced features. It uses the BM25 algorithm, which balances term frequency and document length, along with other algorithms, to rank search results.
For our dense embedding model, we used Jina AI's latest model, jinaai/jina-embeddings-v2-base-en for all datasets except the NQ dataset, where we used Open AI's text-embedding-3-large model.
For the sparse embedding model, we used the latest iteration of SPLADE, naver/splade-v3.
For hybrid vector search, we tried weighing the dense and sparse vector distances equally, and weighing them by 0.8 and 0.2 respectively.
We used Postgres on Lantern Cloud with the Lantern and pgvector extensions installed.
Results
Below, we highlight results for the metrics recall@5 and NDCG@5. Recall@5 measures the proportion of relevant documents that are retrieved among the top 5 results, while NDCG@5 (Normalized Discounted Cumulative Gain) measures the quality of the ranking of the top 5 results.
Full results, including NDCG, MAP, recall, and precision at 1, 3, 5, 10, 100, and 1000, can be seen in the Jupyter notebook.
Key Findings
Dense vectors outperformed Elasticsearch across all datasets except for Scifact, and consistently outperformed sparse vector search for all datasets.
Typically, distances between our dense vectors and the query were lower than distances between our sparse vectors and the query. As a result, weighing the dense vector and sparse vector distances equally in hybrid vector search resulted in worse performance by overemphasizing the sparse vectors.
Weighing the dense vectors more heavily than the sparse vectors by 4 to 1 in hybrid vector search improved performance across all datasets, and achieved better results than dense vector search, sparse vector search, and Elasticsearch.
These results highlight the benefits of combining the strengths of both sparse and dense vectors to improve search quality.
Recall @ 5
Dataset | ElasticSearch | Dense Vectors | Sparse Vectors | Hybrid Search (0.8 / 0.2) |
|---|---|---|---|---|
Scifact (5k) | 0.7479 | 0.70894 | 0.74461 | 0.75511 |
SCIDOCS (25k) | 0.1190 | 0.13512 | 0.10858 | 0.14332 |
FiQA-2018 (57k) | 0.2433 | 0.38519 | 0.2556 | 0.40137 |
Quora (523k) | 0.8495 | 0.91103 | 0.8422 | 0.95348 |
NQ (2.68m) | 0.3800 | 0.52798 | 0.30924 | 0.55516 |
NDCG @ 5
Dataset | ElasticSearch | Dense Vectors | Sparse Vectors | Hybrid Search (0.8 / 0.2) |
|---|---|---|---|---|
Scifact (5k) | 0.6652 | 0.6262 | 0.6495 | 0.67078 |
SCIDOCS (25k) | 0.1350 | 0.1494 | 0.1205 | 0.1572 |
FiQA-2018 (57k) | 0.2268 | 0.3767 | 0.2410 | 0.3828 |
Quora (523k) | 0.7895 | 0.8644 | 0.7949 | 0.8722 |
NQ (2.68m) | 0.2832 | 0.4131 | 0.2203 | 0.43146 |