Vector support in Postgres has significantly improved over the past year. For large datasets, however, initial index creation and reindexing can still be a performance bottleneck.
In this article, we introduce external indexing for pgvector. External indexing addresses this problem by offloading indexing to external machines and returning the completed index to Postgres. This minimizes the impact of indexing on database performance.
This builds on our prior work with external indexing for Lantern's Postgres vector extension and improves the architecture.
Index creation is resource-intensive
In v0.6.0, pgvector introduced parallel index creation. This allows the allocation of more database CPU resources to speed up indexing. However, creating an index over a large number of vectors can still be time-consuming even with parallelism. For example, in our experiments, indexing 5M vectors with 32 vCPUs took about 24 minutes.
Furthermore, recreating the index periodically is often necessary. Over time, a large number of updates and deletes will cause index degradation. This is due to the deleted nodes still taking up space in the HNSW graph, causing index bloat and reducing recall due to unreachable nodes.
Resource-intensive indexing has tradeoffs
The compute resources spent on index creation means that CPUs are not available to serve other queries. This can cause performance degradation during the index creation time.
You can temporarily increase the size of your instance to compensate, and then restore it once index creation is complete. However, this can cause some downtime during both the scaling up and scaling down phase.
With external indexing, we avoid hogging the database resources and allow temporarily scaling up resources without downtime.
External Indexing
Previous Approach
We previously implemented external indexing for Lantern. It was a standalone CLI application that
- Queried the database rows
- Created an HNSW index over the vectors using usearch
- Imported the created index back into the database
This approach had several limitations:
- Partial indexes are not supported because rows were being queried outside of Postgres
CREATE INDEX CONCURRENTLYwas not supported- It required a lock on the table to ensure table tids did not change during indexing
New Approach
With the new external index protocol, external indexing became a first-class member of the Postgres CREATE INDEX API.
We modified pgvector to support connecting to the external indexing server via TCP socket from the database. This allows us to send the tuples over the network to the server where the actual indexing process happens. After indexing, the index file is streamed back into the Postgres instance for use.
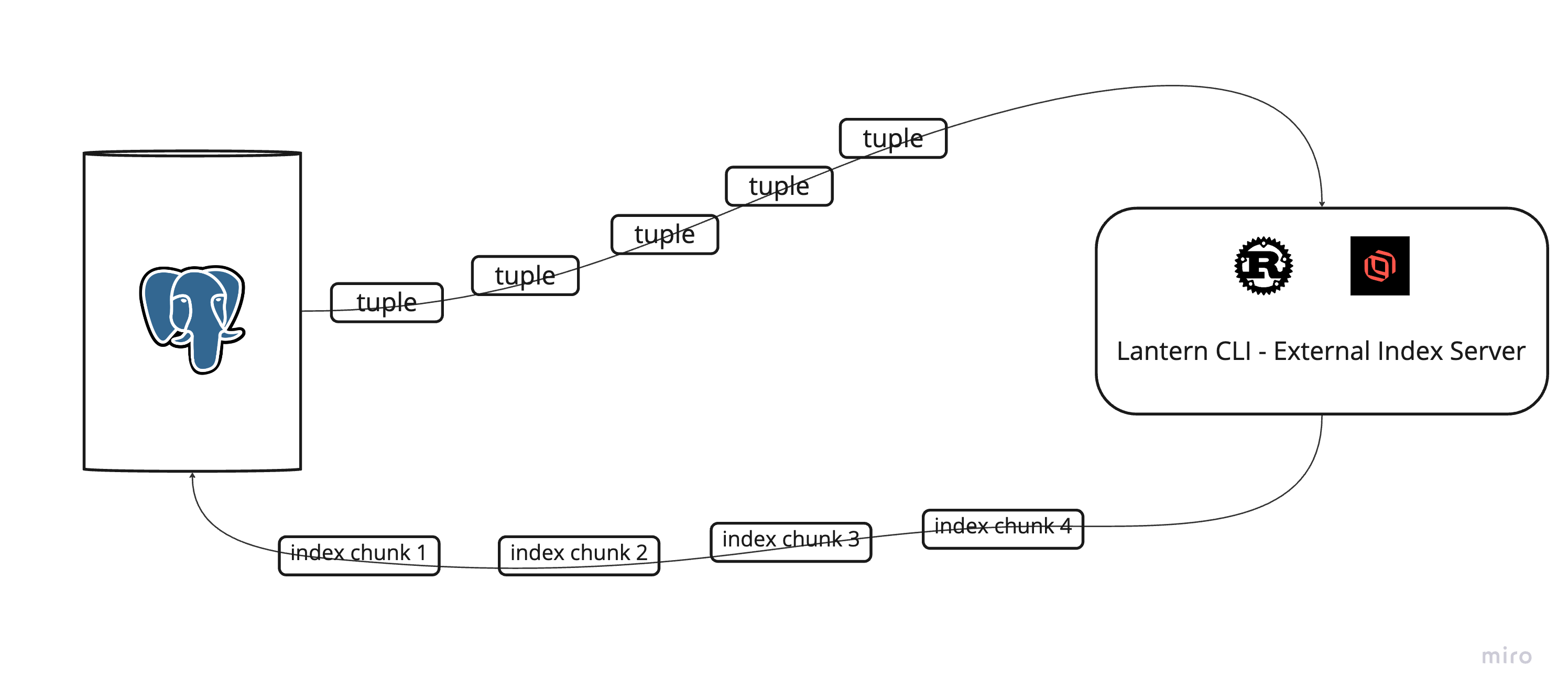
Writes to the table during index creation are handled in the same way concurrent index creation normally handles it in Postgres - CREATE INDEX locks the table, CREATE INDEX CONCURRENTLY does not. With concurrent indexing, Postgres notes any write operations that happened during index creation, and updates the index according to those changes.
Running External Indexing
Let’s see it in action.
First, we will run an external indexing server using lantern-cli with a self-signed certificate.
$ lantern-cli start-indexing-server --cert /tmp/cert.pem --key /tmp/key.pem
[*] [Lantern External Index] External Indexing Status Server started on 0.0.0.0:8999
[*] [Lantern External Index] External Indexing Server started on 0.0.0.0:8998Then, we need a Postgres instance with our custom version of pgvector installed (0.7.4-lanterncloud).
$ psql postgres
postgres@hostname# \dx
List of installed extensions
Name | Version | Schema | Description
---------+--------------------+------------+-------------------------------------------------------
lantern | 0.3.4 | public | Lantern: Fast vector embedding processing in Postgres
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
vector | 0.7.4-lanterncloud | public | vector data type and ivfflat and hnsw access methods
(3 rows)External indexing is configured with the following GUC variables:
hnsw.external_index_host: hostname of the external indexing server (default: 127.0.0.1)hnsw.external_index_port: port of the external indexing server (default: 8998)hnsw.external_index_secure: whether to initiate SSL connection using OpenSSL (default: yes)
postgres@hostname# show hnsw.external_index_host;
hnsw.external_index_host
--------------------------
127.0.0.1
postgres@hostname# show hnsw.external_index_port;
hnsw.external_index_port
--------------------------
8998
postgres@hostname# show hnsw.external_index_secure;
hnsw.external_index_secure
----------------------------
onFinally, we just run our regular CREATE INDEX statement with the external=true option.
postgres@hostname# CREATE INDEX ON openai_500k USING hnsw(embedding vector_cosine_ops) WITH (m='16',ef_construction='128', external='true');
INFO: connecting to external indexing server on 127.0.0.1:8998
INFO: successfully connected to external indexing server
INFO: indexed 500000 elements
CREATE INDEX
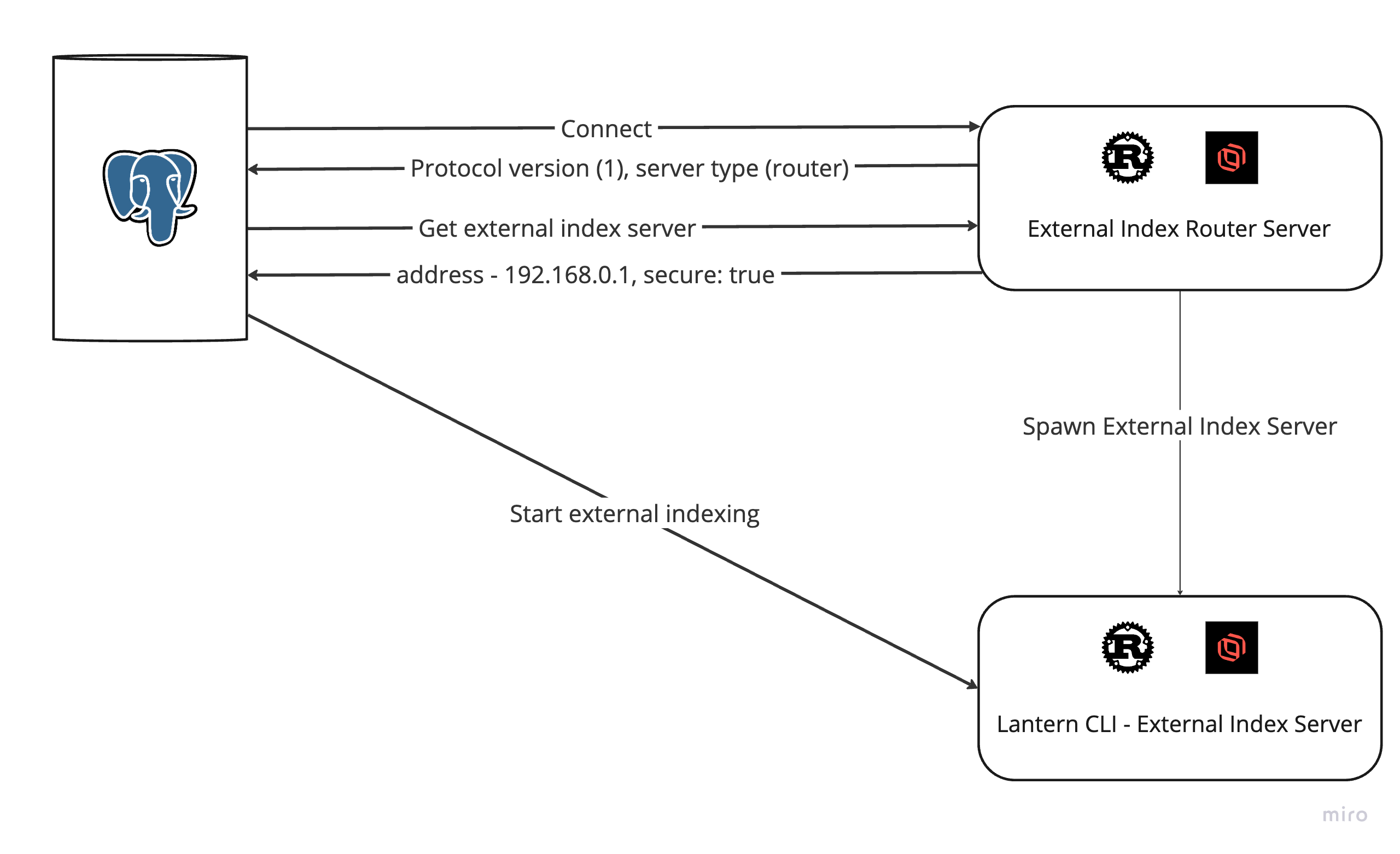
Time: 181322.057 ms (03:01.322)For advanced workloads the external indexing protocol also supports router servers, which are designed to spawn external indexing servers on-demand.
Benchmarks
To understand the performance benefits of external indexing, we conducted a benchmark using a dataset of 500,000 Open AI vectors from VectorDBBench.
Setup
- Database instance: Lantern Cloud (8vCPU, 30GB RAM)
- pgbench Server: 8vCPU, in the same region
- External Indexing server: 32vCPU
We ran pgbench under three different scenarios:
- Baseline TPS: No concurrent indexing activity
- In-Database Parallel Indexing: HNSW index creation using 8 parallel workers inside the Postgres instance
- External indexing: HNSW index creation offloaded to an external machine using the external indexing protocol
We verified that recall was the same for both in-database and external indexing - about 93%.
Baseline TPS
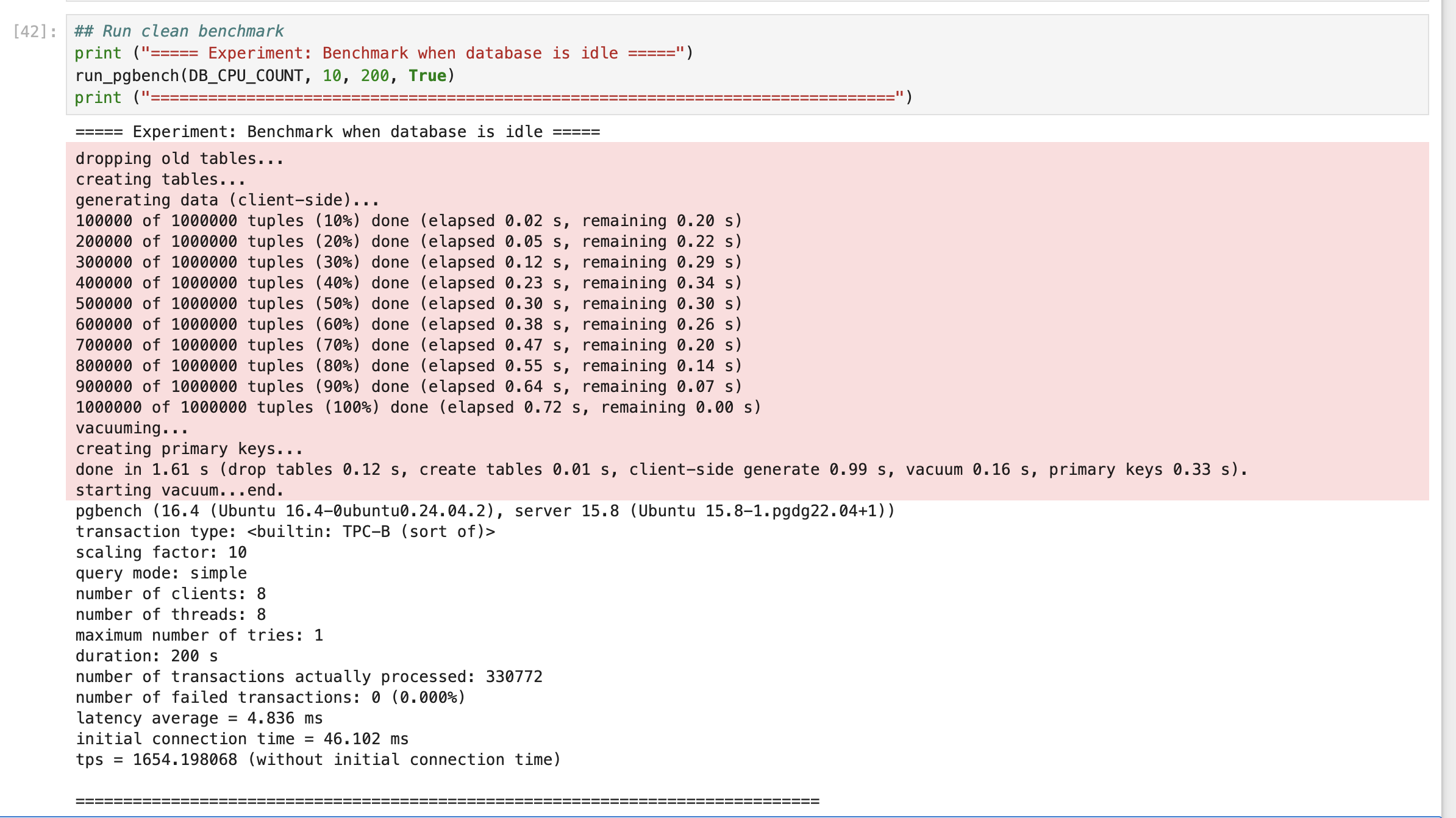
After loading data into the database, first we will run pgbench on an idle database to see the TPS of the database when there are no other operations going on in parallel.
In-Database Parallel Indexing
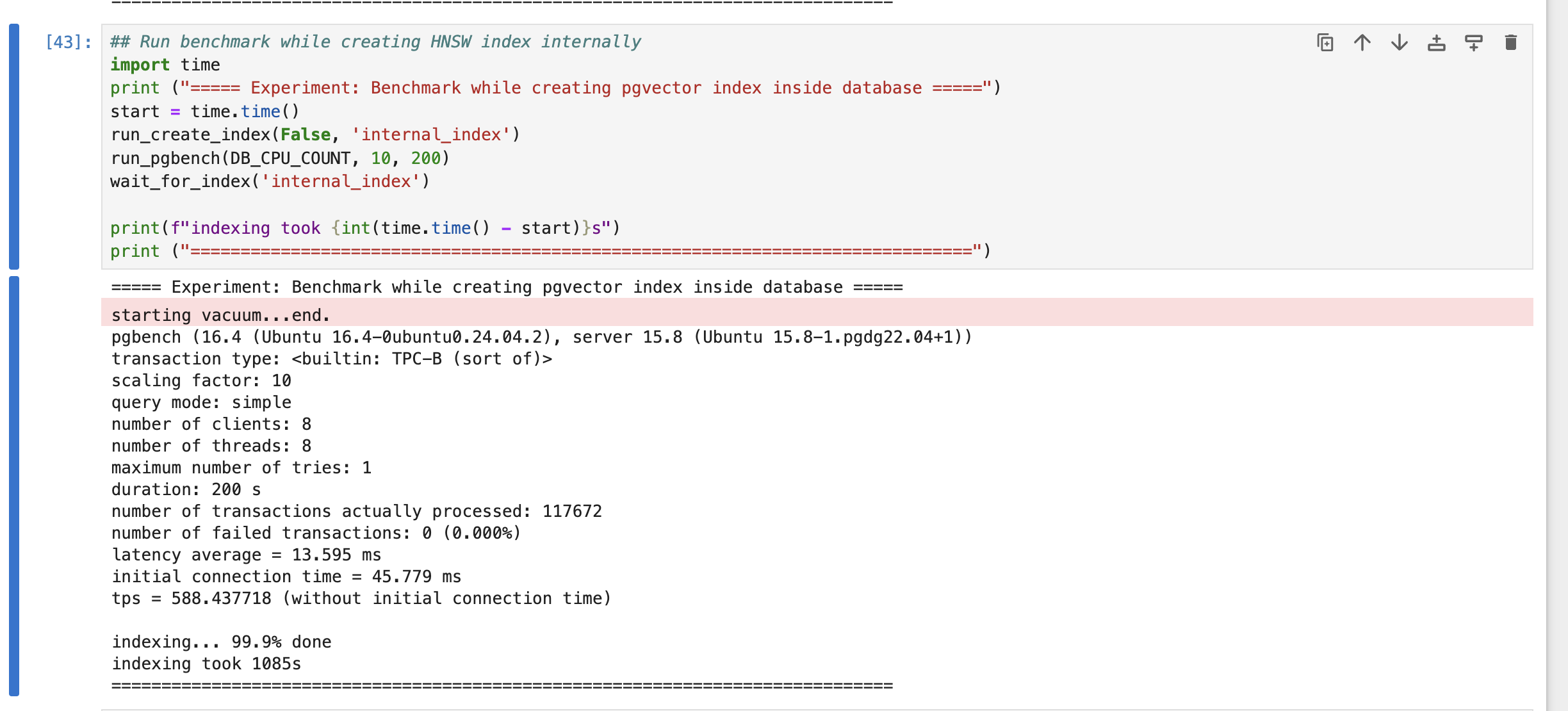
Then we will run pgbench while creating HNSW index without external indexing using 8 parallel workers.
External Indexing
Lastly, we'll run the same experiment, but offload the indexing process to a remote server by using the external indexing.
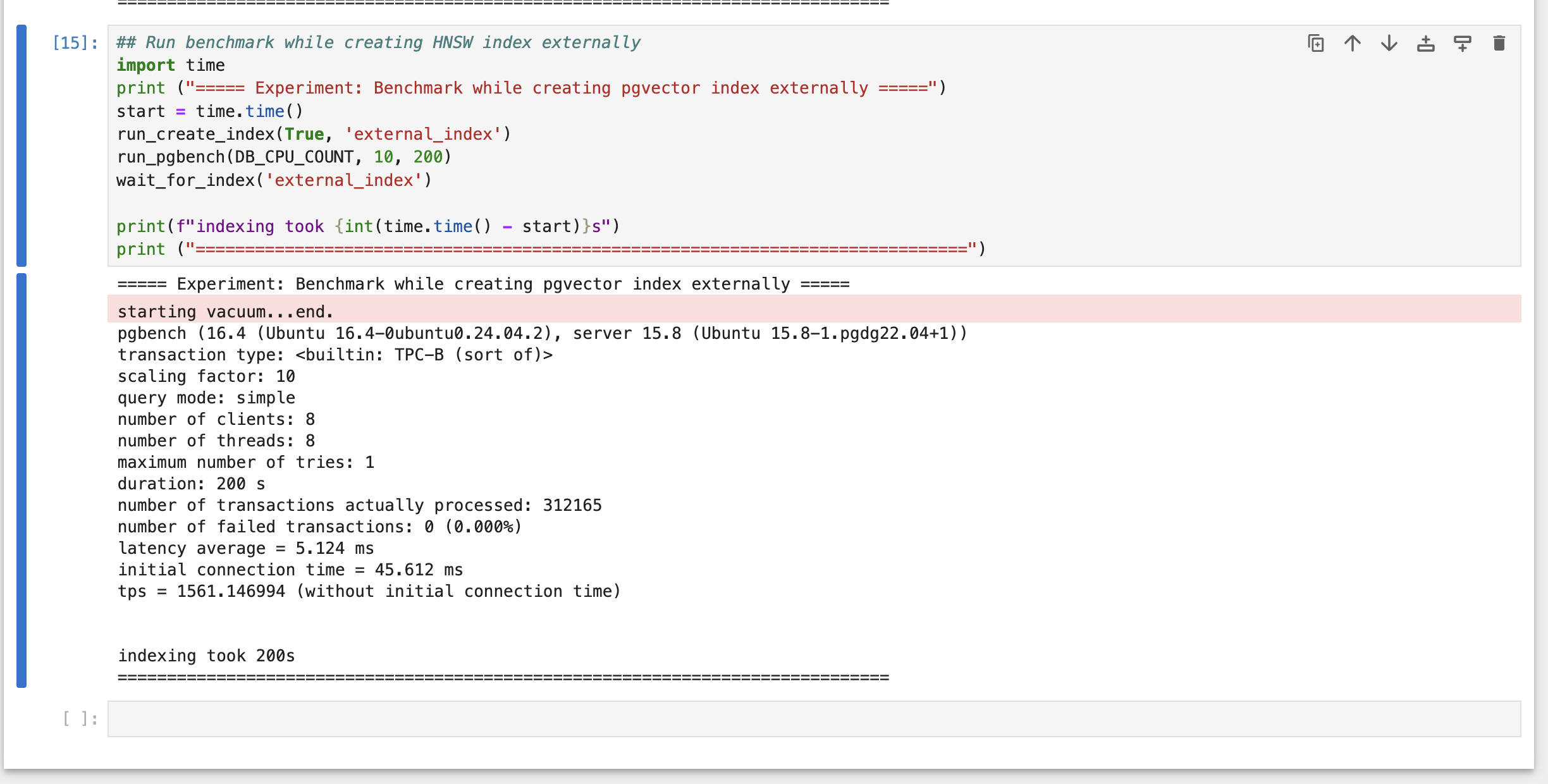
Results
Setup | Transactions Per Second | Indexing Time (s) |
|---|---|---|
Baseline TPS | 1654 | N/A |
In-Database Parallel Indexing | 588 | 1085 |
External Indexing | 1561 | 200 |
As we can see, external indexing allows us to index large datasets by having very little affect on performance compared to parallel indexing inside the database which is critical for production workloads.