Creating a vector index with pgvector is straightforward - just run CREATE INDEX ON t USING hnsw(col vector_l2_ops). But what is actually going on under the hood as we run this and insert or modify data?
In this article, we'll take a deep dive to understand the underlying index file created by pgvector in Postgres.
Overview of Postgres Storage
Let’s take a quick recap on how Postgres stores data before diving into pgvector's index storage.
Postgres stores relations, i.e., tables and indexes, in files on disk. Each file is logically divided into pages, where each page is 8KB by default. A page generally has the following structure:
Item | Description |
|---|---|
ItemIdData | Array of item identifiers pointing to the actual items. Each entry is an (offset, length) pair. 4 bytes per item. |
Free space | The unallocated space between the right-most ItemId and the left-most Item on the page. New item identifiers are allocated from the start of this area, new items from the end. |
Items | The actual items themselves. |
Special space | Index-access-method specific data. Different methods store different data. Empty in ordinary tables. |

Aside: One might ask, why even have ItemID? Why not just list items one after another? The answer is that the current design allows for reordering. Entities outside of the page refer to the page by ItemID, and only the page itself is aware where the corresponding item is. This means that if some items are deleted, and there is fragmentation on the page, Postgres can internally defragment and reorder items, without worrying about external references.
For more details, refer to Postgres' documentation.
pgvector Index Metadata Page
The pgvector HNSW index pages are separated in two categories: the metadata page (page 0) and rest of the pages, which contain the HNSW graph.
The metadata page contains the Postgres page header (required for every page), a struct HnswMetaPageData, and a struct HnswPageOpaqueData at the end of the page.
Visually, the metadata page has the following structure:

HnswMetaPageData
The HnswMetaPageData struct contains metadata for managing the HNSW index. This defines the configuration and operational parameters of the HNSW graph.
typedef struct HnswMetaPageData {
uint32 magicNumber;
uint32 version;
uint32 dimensions;
uint16 m;
uint16 efConstruction;
BlockNumber entryBlkno;
OffsetNumber entryOffno;
int16 entryLevel;
BlockNumber insertPage;
} HnswMetaPageData;magicNumber → constant which is 0xA953A953 hex number, used to detect early potential header corruption or accidental page structure mismatch.
version → contains the index layout version (which is 1 for now). This can help to differentiate index files if there will be breaking changes on how the index is stored in disk.
dimensions → the dimensions of the Vector element
m → HNSW parameter that determines the maximum number of connections (or edges) a node (or data point) can have in the graph
efConstruction → HNSW parameter that determines the number of candidate neighbors to explore during the construction phase for each element
entryBlkno and entryOffno → the position in index pages for the entry element of HNSW graph
entryLevel → level of the entry element in the HNSW graph
insertPage → Postgres index page number where new elements should be inserted
HnswPageOpaqueData
The HnswPageOpaqueData is used for page management within the index. It helps organize the index pages.
typedef struct HnswPageOpaqueData {
BlockNumber nextblkno;
uint16 unused;
uint16 page_id; /* for identification of HNSW indexes */
} HnswPageOpaqueData;nextblkno → block number of the next page (used in vacuum operation)
unused → reserved for later use
page_id → to mark that the page is HNSW index page
pgvector Index Pages
After the metadata page, come the index pages, containing the core components of the index. pgvector's HNSW index pages have the following structure:

It follows the general structure of Postgres pages. It starts with the PageHeaderData and ends with the special space. The ItemIdData space contains the Line Item Pointers array, which are relative offsets in bytes to each element in the page, The actual index elements are stored in the Items space.
The index elements are divided into 2 types: element tuples and neighbor info tuples.
Element Tuple
The element tuple contains information about an HNSW graph node. The underlying structure is below.
typedef struct HnswElementTupleData {
uint8 type;
uint8 level;
uint8 deleted;
uint8 unused;
ItemPointerData heaptids[10];
ItemPointerData neighbortid;
uint16 unused2;
Vector data;
} HnswElementTupleData;type → constant indicating if tuple is neighbor info element or the actual graph element. For element tuples it will be HNSW_ELEMENT_TUPLE_TYPE (1)
level → element’s level in HNSW graph
deleted → after vacuum (non-full) if all table row’s for the element are deleted, the element is marked as deleted and it’s data is zeroed. Then this element can be overwritten during new inserts thus saving storage.
unused and unused2 → these properties are not used currently and are reserved for future use to not change the storage layout.
heaptids[10] → this is the TID array pointing to actual table rows. You might think that a single property heaptid would be enough as each graph element will have one to one mapping with the table rows, but there is an optimization in pgvector for two cases:
- duplicate elements will be inserted in the table
- non-HOT updates which will increase the index size
neighbortid → TID pointer to the tuple inside index pages which contains information about nearest neighbors for the element.
data → this is the vector data
Neighbor Info Tuple
Now let’s look at the neighbor info tuple, which provides information about the neighbors of a graph node. The underlying structure is below.
typedef struct HnswNeighborTupleData
{
uint8 type;
uint8 unused;
uint16 count;
ItemPointerData indextids[FLEXIBLE_ARRAY_MEMBER];
} HnswNeighborTupleData;type → constant indicating if tuple is neighbor info element or the actual graph element. For neighbor tuples it will be HNSW_NEIGHBOR_TUPLE_TYPE (2)
unused → reserved for future use
count → size of indextids array
indextids → TID pointers inside index pages (neighbors for the element). The size of this array depends on M parameter of graph and level of the element and is calculated like: (level + 2) * m
Visualizing Index Pages
Let’s try to visualize the connections of index tuples by mapping structs to JSON representations to better understand what is happening under the hood.
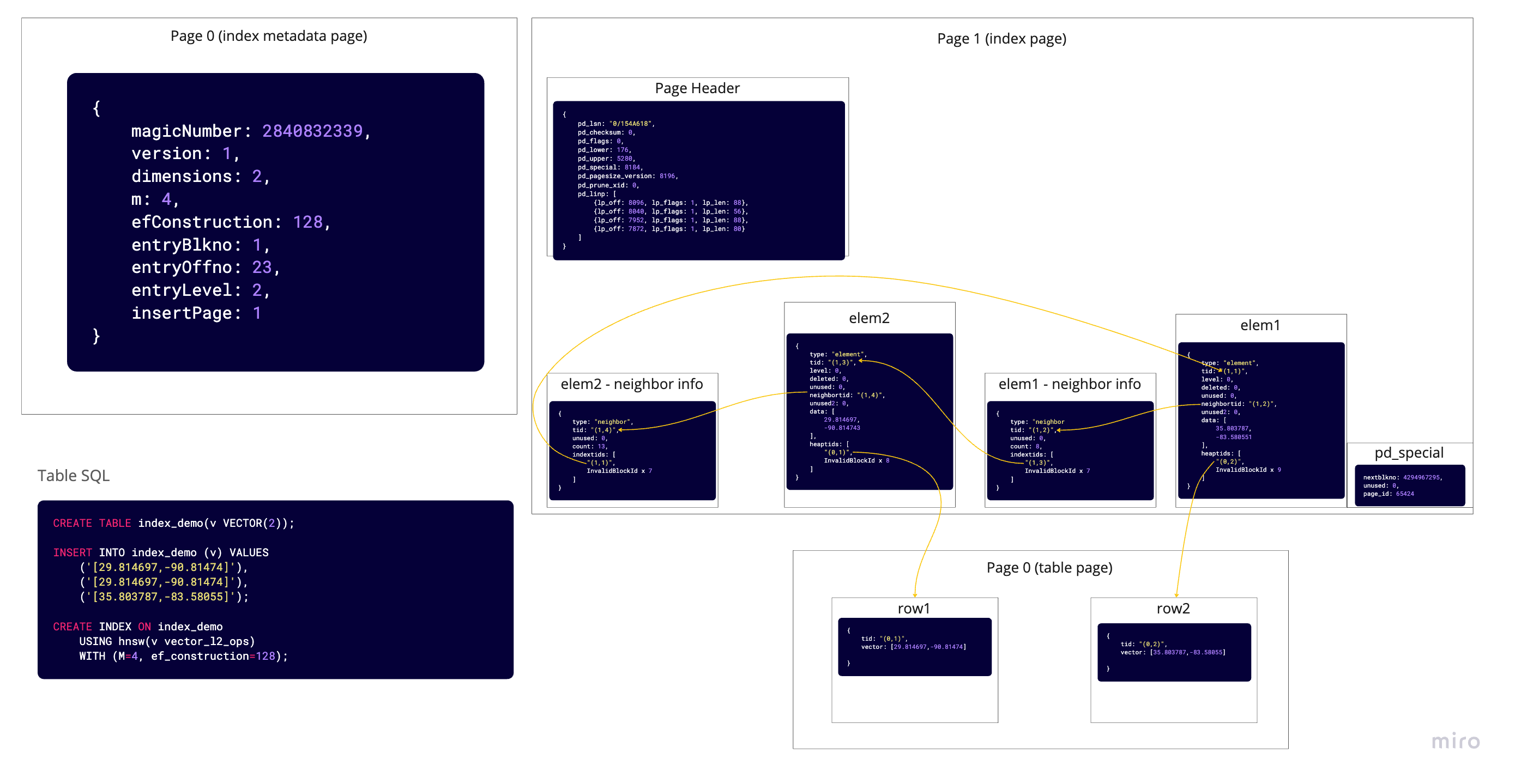
In this case, we have created a table with 2 rows. Then, we created an HNSW index over the data. For this, pgvector will create 2 index pages: metadata page (page 0) and a page to keep HNSW graph. We can see that there are 4 tuples inserted on the index page: one for each row's element tuple and one for each row's neighbor info tuple.
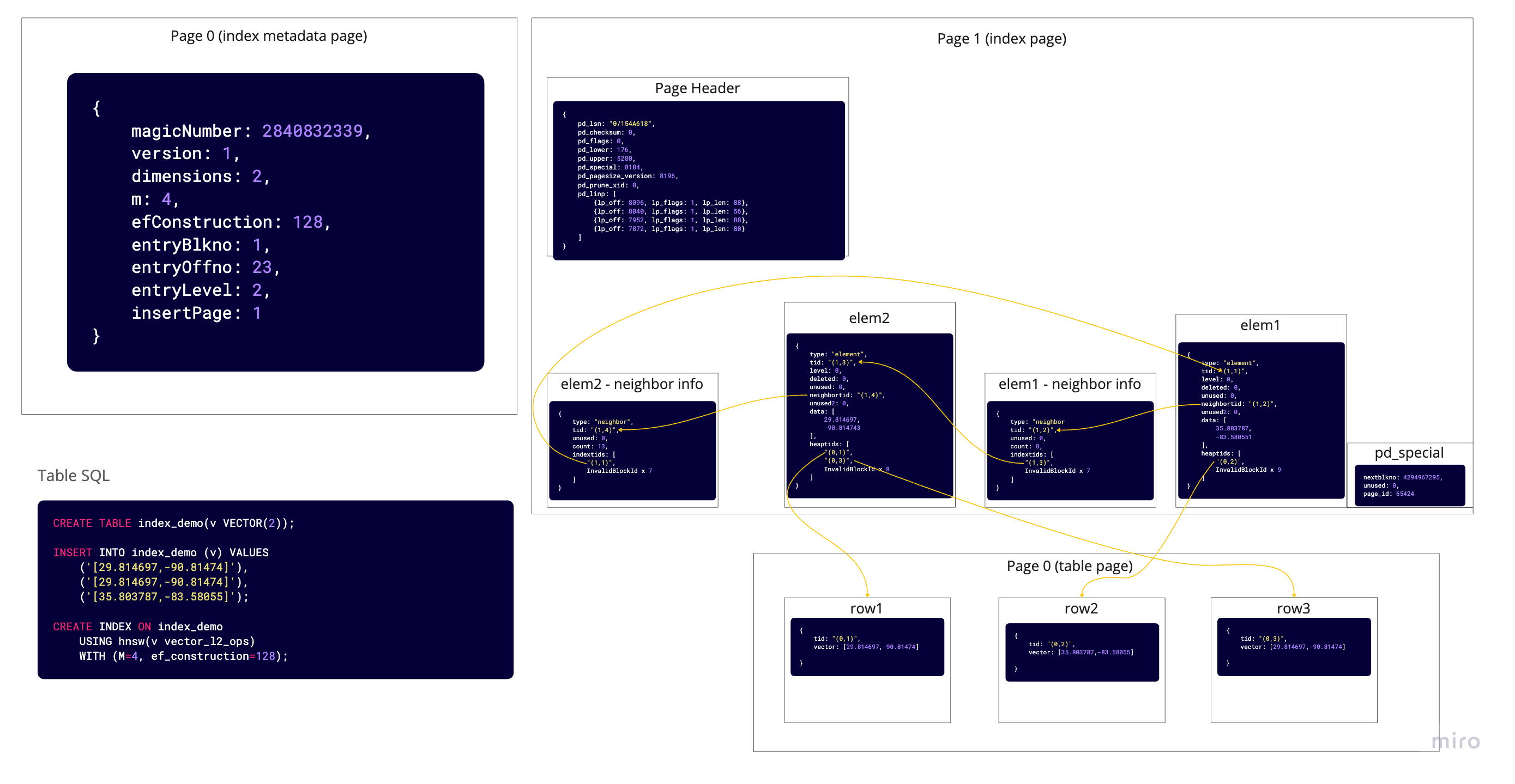
Then when we insert a new row in the table which has the same value as the first row. One might expect a new element and neighbor tuple to be added on the index page for the row, but due to the optimization we mentioned earlier — the value of the first and third rows are the same, they will share one element tuple and one neighbor info tuple. The element tuple's heaptids array will contain pointers to both the first and the second row.
Mapping hexdump of index file to structs
Now let’s see how the actual bytes are mapped to the structs described above.
First, we'll generate a hexdump of the index file. To locate the file we can use the following query:
testvec@hostname| 64046=# SELECT pg_relation_filepath('index_demo_v_idx');
pg_relation_filepath
----------------------
base/1154333/1172326
(1 row)Now we can find the index file under $PGDATA/base/1154333/1172326
We can observe that the file is 16KiB in size, which means there are 2 pages (as each page is 8KiB in Postgres by default).
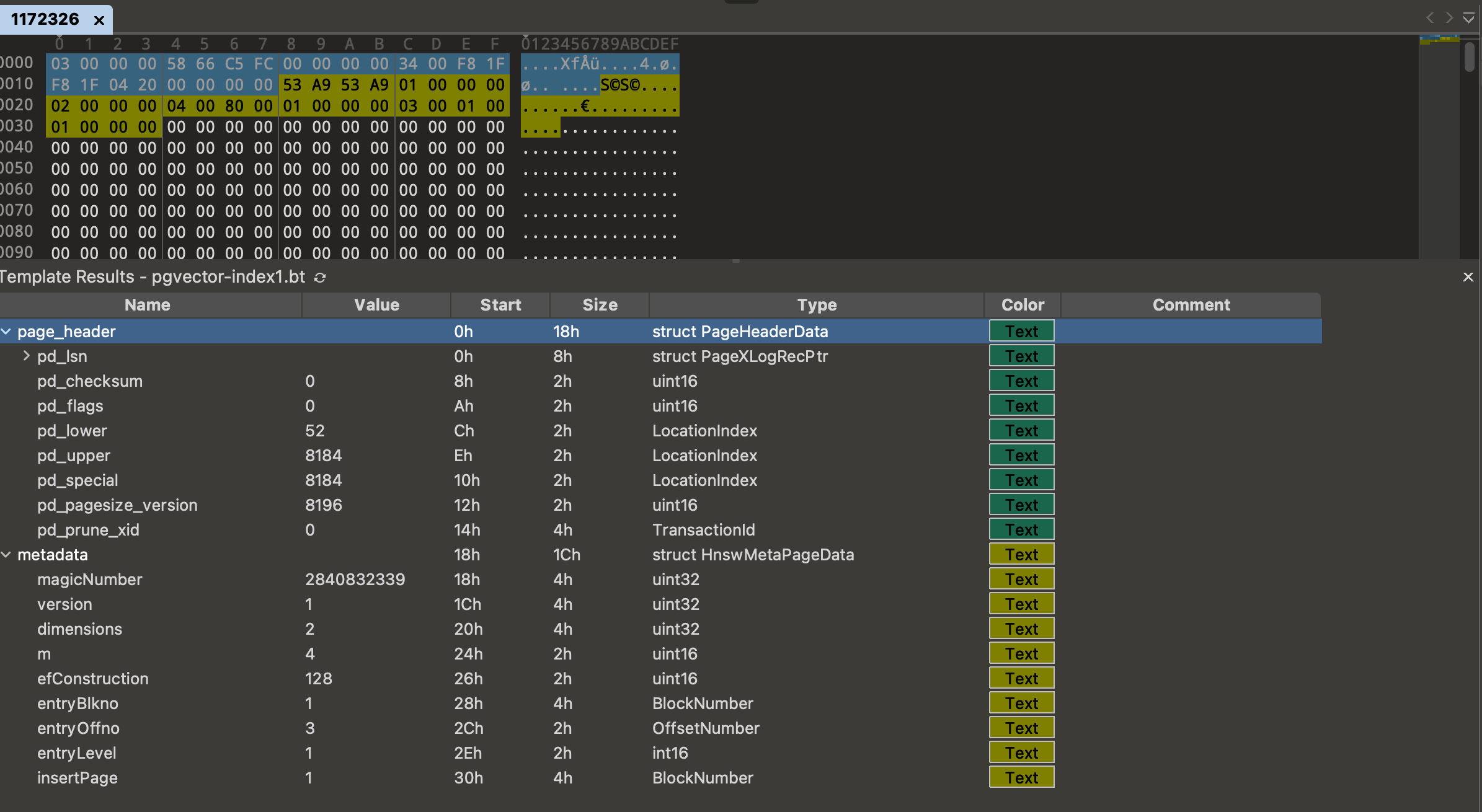
Using the 010 editor and templates, we can map the hex bytes to pgvector structs. On the first page, we can see the PageHeaderData and HnswMetaPageData structs:
Immediately after the special section (pd_special) of the metadata page, the first index page begins. This page's header contains line pointers (pd_linp) with 4 elements:
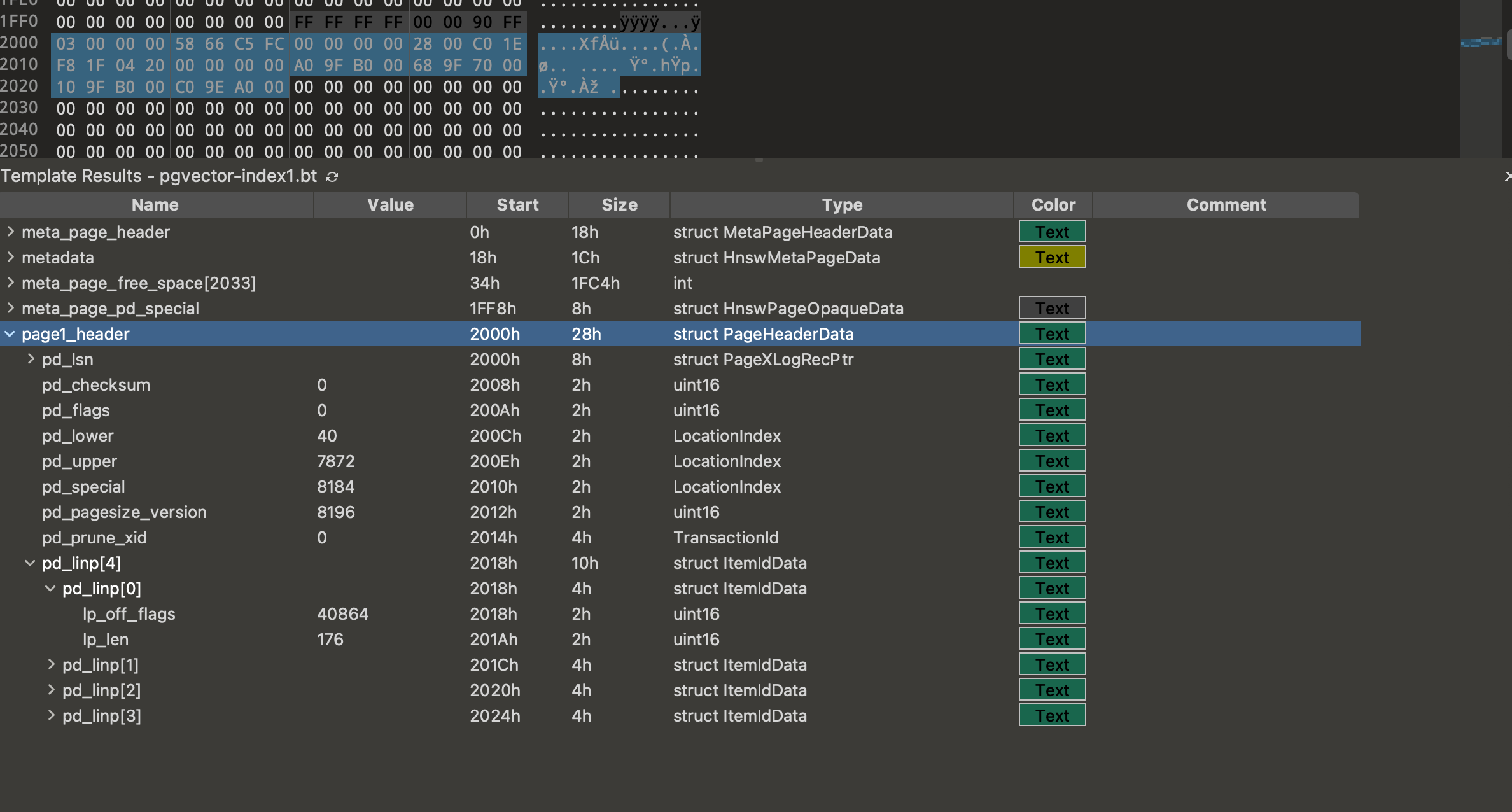
After the free space, we can find the index elements (element tuples and neighbor info tuples):
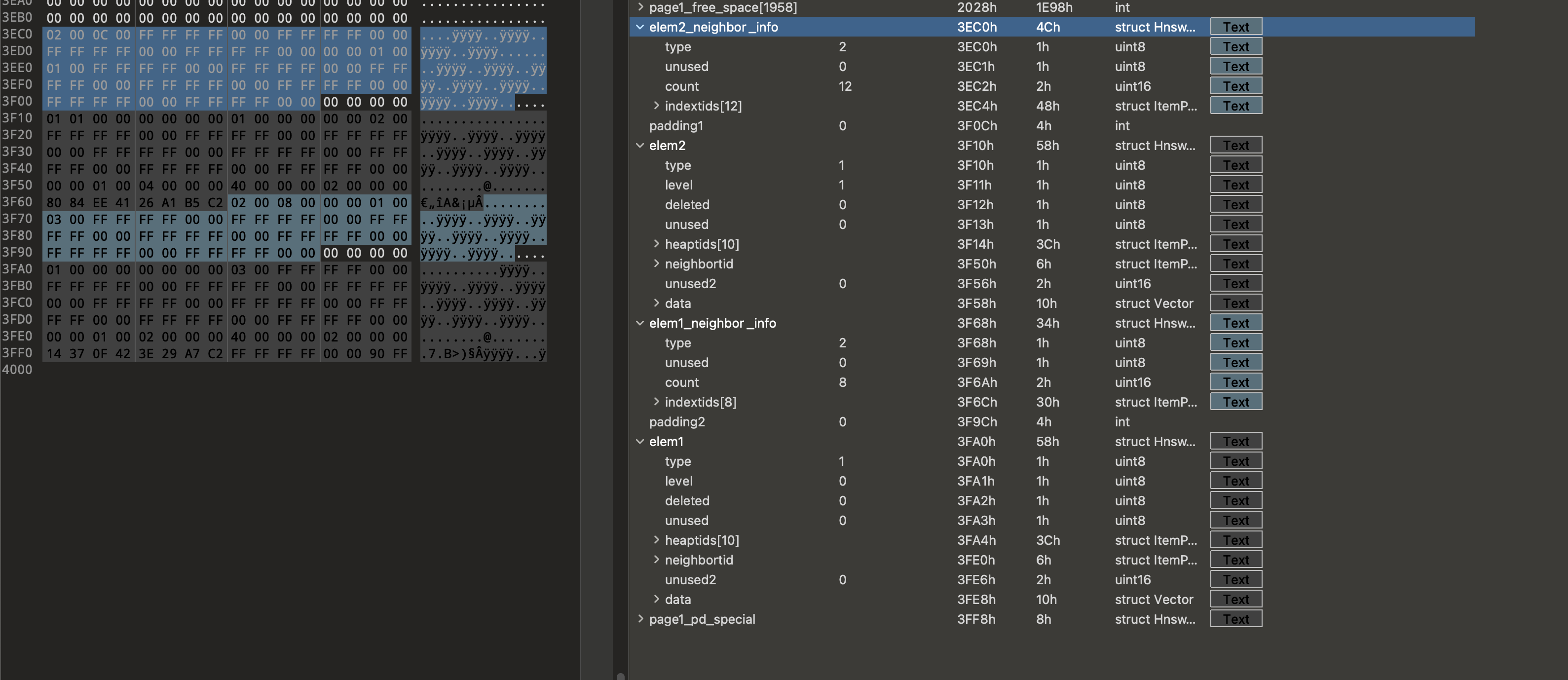
pgvector Index to JSON
To improve our understanding of the pgvector index, we built an index parser in C that converts pgvector’s HNSW index into JSON format. We ported this parser to WASM and built an interactive demo using PGlite to better visualize the storage layout of pgvector’s HNSW index.
In the video below, we first build an index over 60 vector elements which has 2 dimensions, then we delete 10 random rows and call vacuum. After the vacuum we can see that the deleted tuples are marked as deleted and the insertPage in metadata was set to the first page, but after full vacuum we can see that the marked tuples are actually deleted and space is freed up in the disk.