Overview
In 2024, it should be clear what the advantages of vector databases are. While traditional databases like Postgres and MongoDB excel at quantitative data and keyword search, they fall behind in semantic search - understanding the intent behind the search query.
Large-language-models, on the other hand, are excellent at giving us content in a coherent manner. Ask a question in natural language, get a response in natural language. Of course, there are downsides. They struggle with hallucinations and information retrieval outside of their training data.
That’s where vector databases come in.
Vector databases solve these problems quite well. They are a powerful way to search through documents to return the relevant information for a query. Hybrid semantic and keyword search is effective in handling accurate information retrieval. They’re also a great storage layer for LLMs - allowing them to retrieve information they weren’t trained on.
There’s a problem, though. Storing your data and searching your data are two very different things. Combining the two poorly can spell disaster for your application performance.
Today, we’ll show you the easiest and most reliable way to do it. We’ll use Postgres as our database, and walk through a few different search technologies. There are pros and cons to each, but ultimately, you’ll see that using Postgres for data storage and search isn’t just possible - it’s the best performance for vector search, especially as you scale.
To start, let’s go over a few search technologies.
Algolia
“Simple, with a few pitfalls”
Algolia is a fantastic search engine to build on top of your infrastructure. Queries are simple and API calls are succinct. It supports most major backend languages and frontend frameworks. Indexing and using the search engine is as simple as an API call.
ElasticSearch
“A large hammer searching for a small nail”
ElasticSearch is a robust, fully-managed search solution meant for large enterprises and complex search situations. It’s the most popular enterprise search engine, and like Algolia, it’s available in most major backend frameworks. Instead of an API call, you host the service (or pay a public cloud provider to do it for you.)
Postgres
“The simplest approach”
Postgres is an open-source database that offers robust search capabilities with solutions like Lantern. It supports many data types, making it an uncomplicated yet powerful database + search solution. Postgres primarily excels in text search.
Now that we have a good overview of the three solutions we’ll be trying, let’s compare what a search query might look like.
Setup - Our Search Problem
Let’s say we’re looking for a great vacation destination.
We’ll use a description (e.g. “My wife and I are good swimmers. I would like to go somewhere tropical with great scuba options that also has all-inclusive resorts.”), some filters (“English-speaking destinations but not expensive”) and a country filter (“France”).
We’ll store all these as Python variables.
desc = "My wife and I are good swimmers. I would like to go somewhere tropical with great scuba options that also has all-inclusive resorts."
filters = "English -Expensive
country = "FR"Each vacation destination has a description including these attributes.
Comparison
Algolia
from algoliasearch.search_client import SearchClient
# Convert Postgres filters to Algolia filters
def convert_to_algolia_filters(input_string):
filters = input_string.split()
algolia_filters = []
for f in filters:
if f.startswith('-'):
algolia_filters.append(f"{f[1:]}:false")
else:
algolia_filters.append(f"{f}:true")
return ' AND '.join(algolia_filters)
# Initialize the Algolia client
client = SearchClient.create('app_id', 'api_key')
index = client.init_index('vacation_destinations')
query = desc
filters = convert_to_algolia_filters(filters + " " + country)
# Execute the search
response = index.search(query, {
'filters': filters,
'hitsPerPage': 3
})
print(response)Pros
- Simple queries
- AI-focused
Cons
- Managed externally
- New query language
- Expensive as you scale
Algolia’s search queries are beautifully simple. Developers and ML specialists looking for an easy search engine to integrate to their embeddings and database will be quite happy with the short learning curve.
Simplicity can be a double-edged sword. It’s true that Algolia manages everything - you just send them your data, and your money. But relying on an external API means a new point of latency - making a search request to an external service and waiting for that response. It's small, but those milliseconds matter. Plus, if Algolia's service is disrupted, yours is too.
What’s worse, separating your index from your data source means maintaining a data sync externally - any update to your database means an update to Algolia too.
While it’s nice to have simple search queries, you’ll need to learn this second query language after you learn SQL. Notice above that we have to convert a Postgres filter to Algolia’s query language.
It’s also important to note that Algolia does query AND storage-based pricing. As you scale, so do your costs, beyond just compute.
ElasticSearch
from elasticsearch import Elasticsearch
es = Elasticsearch()
query = {
"query": {
"bool": {
"must": {
"match": {
"description": {
"query": filters,
"operator": "and"
}
}
},
"filter": {
"term": {
"country": country
}
}
}
},
"script_score": {
"query": {
"script": {
"source": "cosineSimilarity(params.query_vector, 'description_embedding_v2') + 1.0",
"params": {
"query_vector": desc
}
}
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
],
"size": 3
}
response = es.search(index="vacation_destinations", body=query)Pros
- Can handle enterprise-level workloads
- Extensive documentation
- Excellent semantic search
- Managed role-based access control
- No external service
Cons
- Complex with long ramp-up period
- Heavy-handed for your needs
- Features you might not need
- Not built from the ground-up for vectors
- Joins are expensive
ElasticSearch is tempting to use, as it’s the most popular search engine solution for enterprises. That means great support on all major public cloud providers, role-based access control, and extensive documentation. It’s also available to be managed and hosted by you, so (aside from the occasional us-east-1 outage) you’re not relying on any external service or API call.
And if you want smart semantic search, look no further.
Of course, there are tradeoffs. It can be harder to implement and manage ElasticSearch than it is to pick a simpler technology. If you have to choose between a future bottleneck and added complexity now, you’ll probably want to pick the former.
When it comes to high-dimensional data like vectors, ElasticSearch falls a bit short. It’s built first-and-foremost for text-based search and analytics. Higher-dimensional data like vectors can slow down ElasticSearch, consuming more of your resources.
Let’s recall that ElasticSearch stores its data separately than the source, Postgres. Because we have this separate search index, we’ll encounter data sync issues. You’ll need to sync with your Postgres DB, and those index updates take more time as you scale.
Let’s dig deeper into these index issues. ElasticSearch stores documents across objects called shards that make up an index.
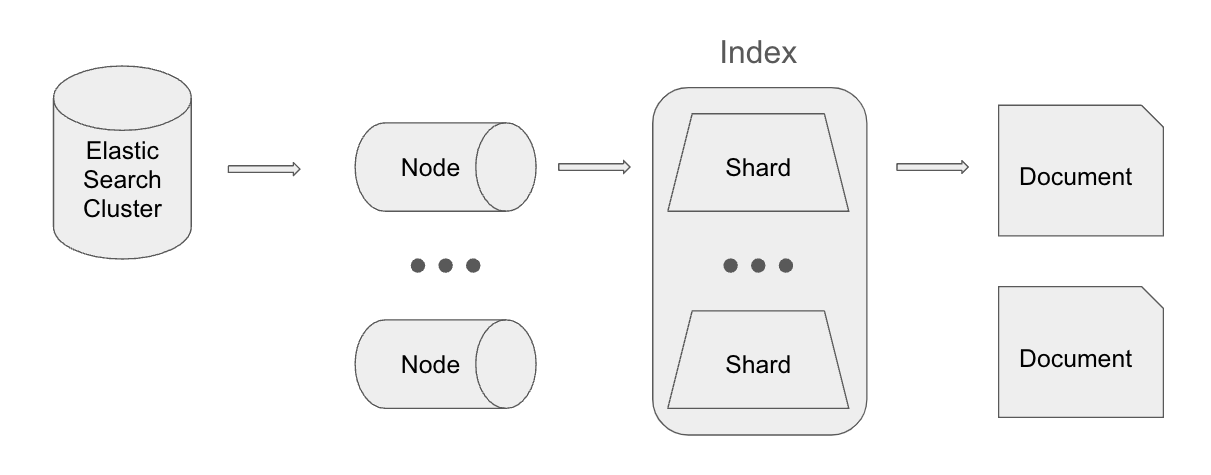
If you wanted to add another criteria like “cities with more than 90,000 people” to your search, ElasticSearch does heavy lifting across nodes to coordinate combining these two tables. This takes more time compared to our last example - Postgres.
Postgres
import psycopg2
conn = psycopg2.connect("dbname='vacation_destinations' user='user' password='pass'")
query = """
SELECT
*,
cos_dist(
text_embedding('BAAI/bge-small-en', $desc),
description_embedding_v2
) AS score
FROM
vacation_destinations
WHERE
country = $country
AND websearch_to_tsquery('english', $filters) @@ description_tsvector
ORDER BY
text_embedding('BAAI/bge-small-en', $desc) <=> description_embedding_v2
LIMIT 3
"""
params = (desc, country, filters, desc)
cursor = conn.cursor()
cursor.execute(query, params)
results = cursor.fetchall()Pros
- One query language
- Zero network latency
- No data sync
- No external service
- Cheap JOINs
- Open-source
Cons
- Non-trivial query language to learn
- Complexity, especially as you add new workloads
Using Postgres as a database and search engine is simple. Postgres is open-source and widely adopted. There’s a strong ecosystem of support and docs. They’ve perfected security and access patterns for 40 years, so the API is powerful and useful.
Now, SQL can have a high learning curve. But using Postgres for search and storage means one query language for both; once you learn once, you can talk to the other.
You can eliminate the worry for latency between storage and search. You don’t need to sync your data with your search engine. Like ElasticSearch, it’s managed and hosted by you or your cloud provider, so you’re not relying on another company for uptime.
And remember how expensive a JOIN is in ElasticSearch? Thanks to Postgres’ architecture, joins are local and inexpensive, compared to Elastic. Updating the query is simple, too.
Let’s again say we want to JOIN on a cities table for our vacation destinations, and filter by population > 90000.
query = """
SELECT
*,
cos_dist(
text_embedding('BAAI/bge-small-en', $desc),
description_embedding_v2
) AS score
FROM
vacation_destinations vd
JOIN
cities c ON vd.city_id = c.id
WHERE
c.population > 90000
AND country = $country
AND websearch_to_tsquery('english', $filters) @@ description_tsvector
ORDER BY
text_embedding('BAAI/bge-small-en', $desc) <=> description_embedding_v2
LIMIT 3
"""Much simpler than ElasticSearch.
Finally, Postgres can get complex as you add features, but the tradeoff is worth it.
Here’s just a few ways you can extend its functionality:
- Time-series events
- Blob storage (more than just text!)
- Advanced analytics
- ML Ops capabilities
Conclusion - which is the best?
By now, it should be clear that the simplest and most scalable solution is Postgres.
- You don't need to learn a new query language, so there's no onboarding. SQL for all database interactions
- No need to maintain and sync a separate data store. One system to manage. Data governance, security are much easier, and latency is better
- Postgres scales well with your data
- You don't rely on another service; no worrying about outages or 6-month learning periods
- Easy vector database addition with complimentary architecture and inexpensive JOINs
Which vector solution should I use for Postgres?
Lantern makes this decision easy. It takes the powers of postgres and combines it with the best parts of vector databases. Their embedding generation is easier than Pinecone + OpenAI - just pick a column and a model. What’s more, indexing is faster, as is SELECT throughput and latency. You get a Postgres database and a vector database in one simple package. And that’s just scratching the surface, with support for embedding generation and maintenance, model A/B testing, vector querying and AI pipeline analytics.
The easiest way to get started with Lantern is to sign up on Lantern Cloud. If you’d like help getting started, or advice on working with embeddings, we’re here to help. Please get in touch at [email protected].