You might have heard the term “vector database” come up in the context of an AI like ChatGPT. You probably had a few questions. Why is a vector database useful for large language models? What benefits does it offer? What is a vector, anyway?
In this article, we’ll walk through what exactly they are. We’ll define the major concepts - vector embeddings, vector indexing, and vector search. At the end, we’ll put them all together.
First, why am I hearing about vectors and vector databases?
It’s been pretty hard to ignore the buzz around ChatGPT. In November 2023, ChatGPT had over 100 million weekly active users.
Large language models (LLMs) like ChatGPT are excellent at communicating with humans and explaining information in a way we understand. People are excited about the promise of LLMs to automate and improve work. For example, Github Copilot has over 1 million paying customers that use it to help write code.
However, there are many things that ChatGPT can’t answer questions about – for example, non-public information that ChatGPT didn’t have access to at training time. Vectors and vector databases can help solve this, so that ChatGPT can truly answer questions about anything.
Let’s learn how this works. We’ll start by introducing vectors.
What is a vector?
A vector is a high-dimensional numerical representation of data. That data can be anything - a photo, a text file, a voice recording. Vectors are objects that have both magnitude and direction.

An n-dimensional vector, where n is the number of floating point numbers
Let’s imagine these vectors simply, as two-dimensional objects. We'll use Vector A to represent the word "pizza" with the value [1,1]. Vector B will be "pasta" and we'll represent it as [2, 1]. These two objects are somewhat similar, but they’re much more similar than tea. We'll represent tea with vector C, which we'll show as [-3, -5].
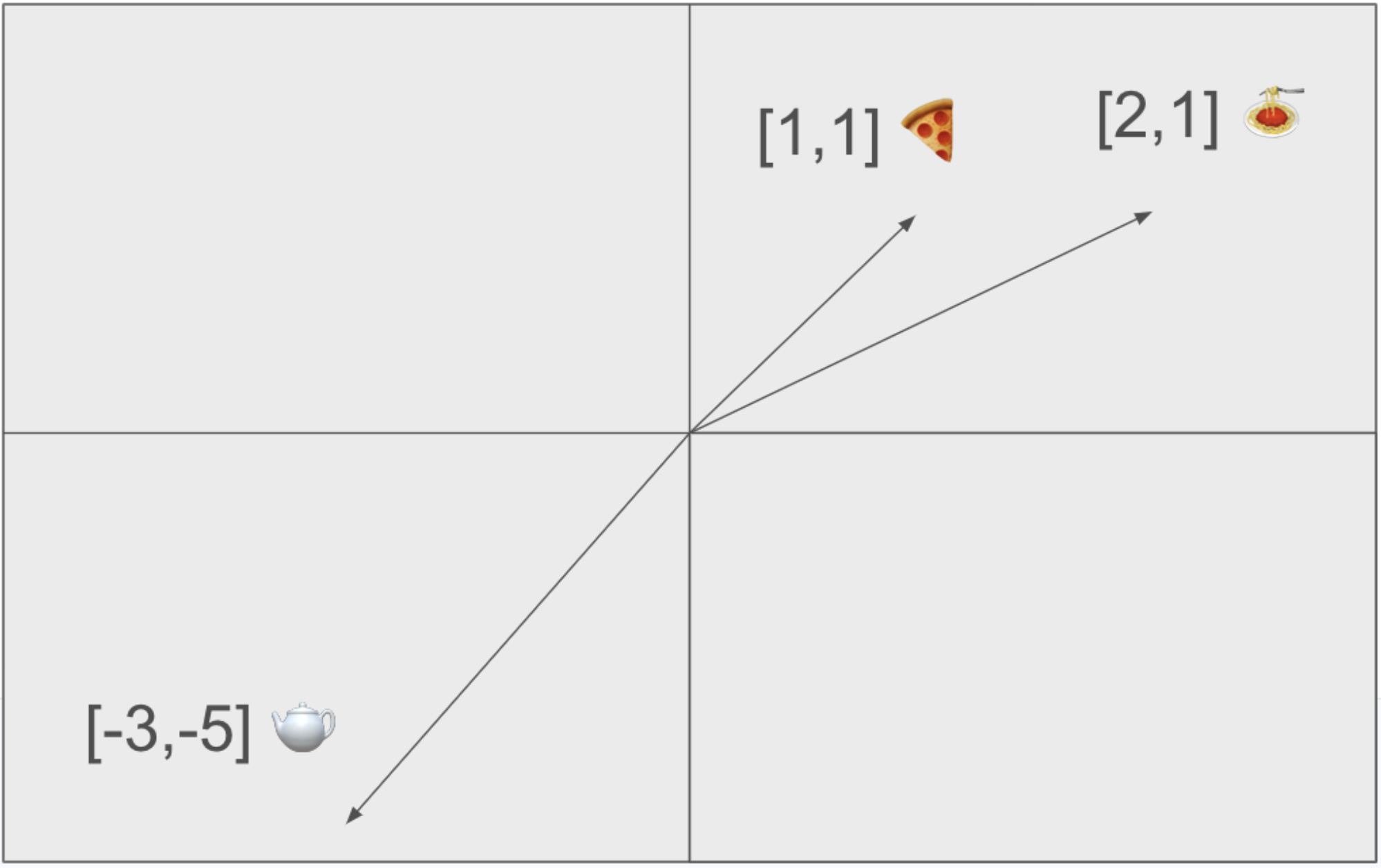
If we wanted to find similar objects to vector A (pizza), we’d ideally pick vector B (pasta) over vector C (tea), because vector B, as we can see, is closer to vector A. In general, the goal of vectors when it comes to AI applications is to get a condensed but meaningful representation of complex data, like text, images, and videos. To convert data to vectors, we can use an embedding model. An embedding model is trained to generate vectors such that the relationships between the vectors capture the underlying relationships between the original objects. That is, two similar objects should have vectors that are close together. Vectors generated from embedding models are also called embeddings or vector embeddings.
How do we compare vectors to see if they’re similar?
The goal of a good embedding model is for two similar objects to map to vectors that are close together. “Close together” is defined by some distance metric. Common distance metrics include euclidean distance, cosine distance, and dot product.
Euclidean distance, for example, measures the straight-line distance between two vectors. The shorter the euclidean distance, the more similar the vector embeddings are.

Cosine similarity measures the cosine of the angle between two vectors, reflecting how similar they are in orientation. Open AI recommends cosine similarity as a distance metric. They note that for their embeddings, the choice doesn't usually matter.
However, if you have a dataset of item-item similarity values, it’s worth running benchmarks to make sure you make an appropriate choice.
How are vectors useful?
Recall the earlier problem: ChatGPT is useful for answering questions, but it can’t answer questions about information it isn’t trained on. To resolve this, we would like to easily search over a corpus of information that ChatGPT doesn’t know about or isn’t deeply familiar with to find relevant context that helps us answer a question, and share it with ChatGPT to help it give an answer.
However, it is hard to search over unstructured data like text. Converting text to a vector representation can allow us to easily perform text search.
For example, a basic text search method might only identify exact matches, finding “runner” and “running” when searching for “run”. Yet, it would miss connections between semantically related but differently worded concepts, such as failing to retrieve "screen" with a search for "monitor" or "external display for my computer". This limitation highlights the difficulty in searching unstructured data using traditional methods.
This is where vectors and powerful embedding models can help. These models can transform data like text into numerical vector representations. These vectors can capture semantic similarity between terms like "monitor," "screen," and "external display for my computer," representing them in a manner that highlights their relatedness. This transformation enables a more nuanced and efficient search capability, where even complex queries can be matched with relevant results through rapid numerical comparisons.
What is a vector database?
A vector database is a database that stores these vectors and allows efficiently retrieving similar vectors, with similarity defined by the distance metric. To enable efficient search, it uses vector indexing methods. We discuss these in greater detail later. The database also stores metadata for filtering results and an ID for identifying the embedding.
Generally, a vector database is used to store vectors of information you want to search over. Let’s imagine you want to search over one million text documents.
First, you store the relevant data in a vector database using the following steps
- We use our embedding model to generate embeddings of all the documents we want to search over.
- We take those embeddings, with their associated data such as the document ID and document type, and store them in a vector database.
To search for a document, you provide a vector that represents what you want the result documents to be similar to.
Imagine you know that you want to find similar documents to document 1. You can query the vector database using document 1’s vector embedding.
Alternatively, you may not have an example of a document you want, but you may be able to describe what the contents should contain. In this case, you can
- We use the same embedding model from earlier to create a vector embedding of our search query. We call this the query vector.
- We use the vector database to compare the vectors in the database to this query vector, and find the similar ones.
These documents represent similar context to the query.
How do vector databases relate to LLMs?
Vectors make LLMs like ChatGPT even more powerful.
As mentioned, the goal of vector databases is to enable efficient search over large amounts of unstructured data. By doing so, it allows us to search over documents, and share context that would be helpful to ChatGPT in answering questions.
This ensures that ChatGPT can answer questions about information it doesn’t otherwise have access to, help it answer questions for which there isn’t a lot of information on the web, or help avoid “hallucinations” by reminding it about facts.
Imagine you have a question about a codebase. With vector databases, you can store all the information that might be helpful to answering the question – documentation, code, pull requests – and automatically retrieve the subset of information that would be helpful to answering questions about a codebase.
Now we have a high-level understanding of what happens when we store items in a vector database. We also understand how we use the same algorithm when we search vector databases. Let’s learn a bit more about each part.
How does a vector database work?
Vector databases enable efficient searches with vector indexes.
At scale, it’s not practical to compare each vector to your query vector, every time you perform a search. Modern compute is powerful; you won’t notice a delay in a database with 10,000 embeddings. Once you get past a few million vectors, you start to measure delay in seconds. You want a data structure that allows you to quickly retrieve the correct data. This is what a vector index enables.
Recall our example from earlier. If we knew we were looking for pasta, we wouldn't bother comparing vectors in the "tea" part of the graph. We know those won't be as similar.
The goal of a vector index is to enable faster retrievals of vector embeddings while maintaining high accuracy. Instead of looking through every vector, find a way to shorten the list of vectors to search.
To do this, vector indexes use approximate nearest neighbor (ANN) algorithms. These algorithms are distinct from k-nearest neighbor (KNN) algorithms, which perform exact search, iterating over every vector to find the nearest k vectors. ANN is better suited for large quantities of data, where retrieval can become slow and hinder application performance.
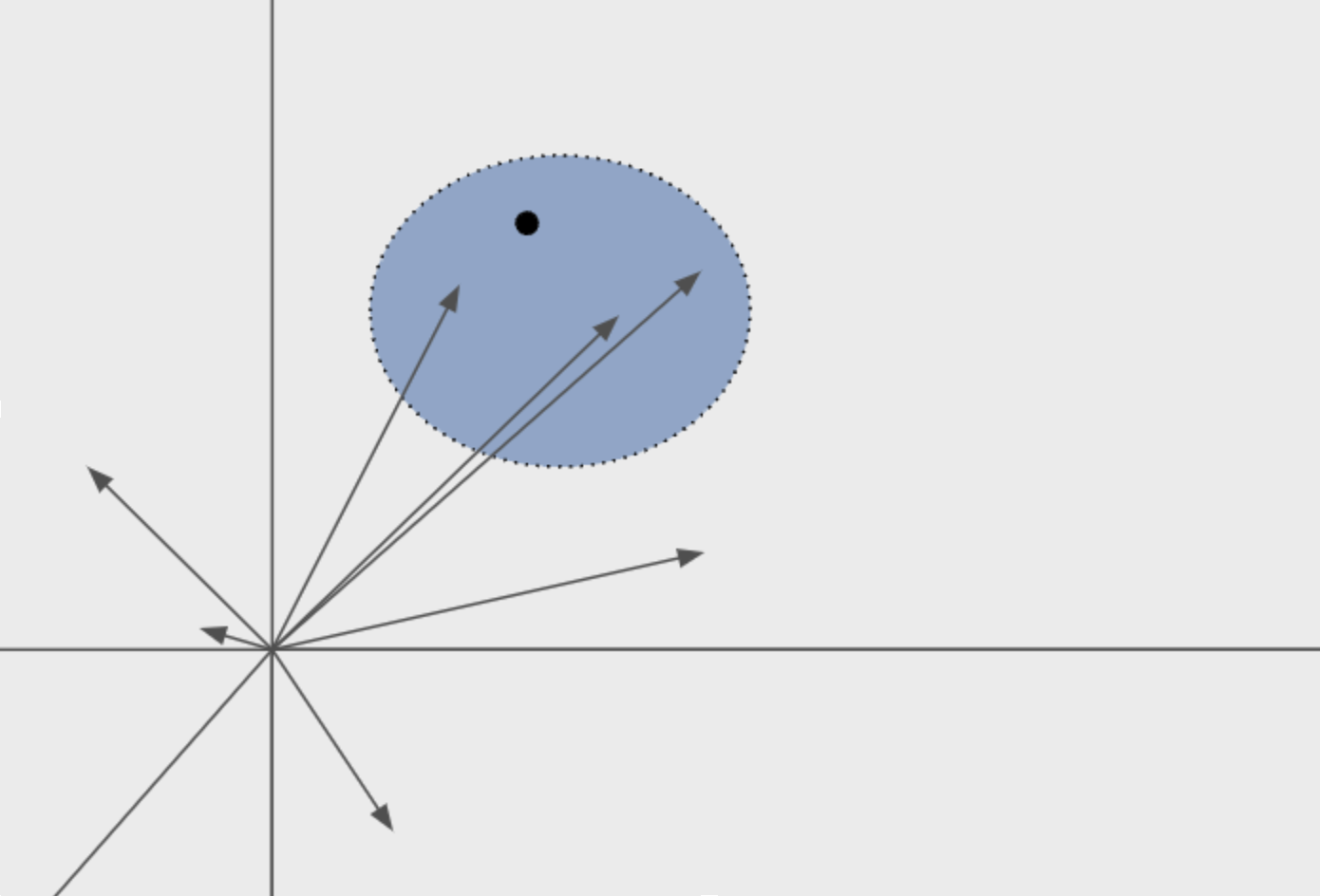
Approximate nearest-neighbors to a point
Hierarchical Navigable Small Worlds (HNSW) is a state-of-the-art ANN algorithm for vector indexing and search. It uses a multi-layered, graph-based approach. It stores all of the vectors in a graph. The top layer of the graph contains a subset of representative vectors from the vector set. Each of these vectors are joined with similar vectors in the next layer. This repeats until the bottom layer, where the bottom later contains all the vectors of the vector set.
To perform a search, you start at the top layer. We then find the nearest neighbors at each level, and traverse the graph from these neighbors, moving further and further down the layers searching through neighbors, and finding at the bottom layer our closest neighbor.
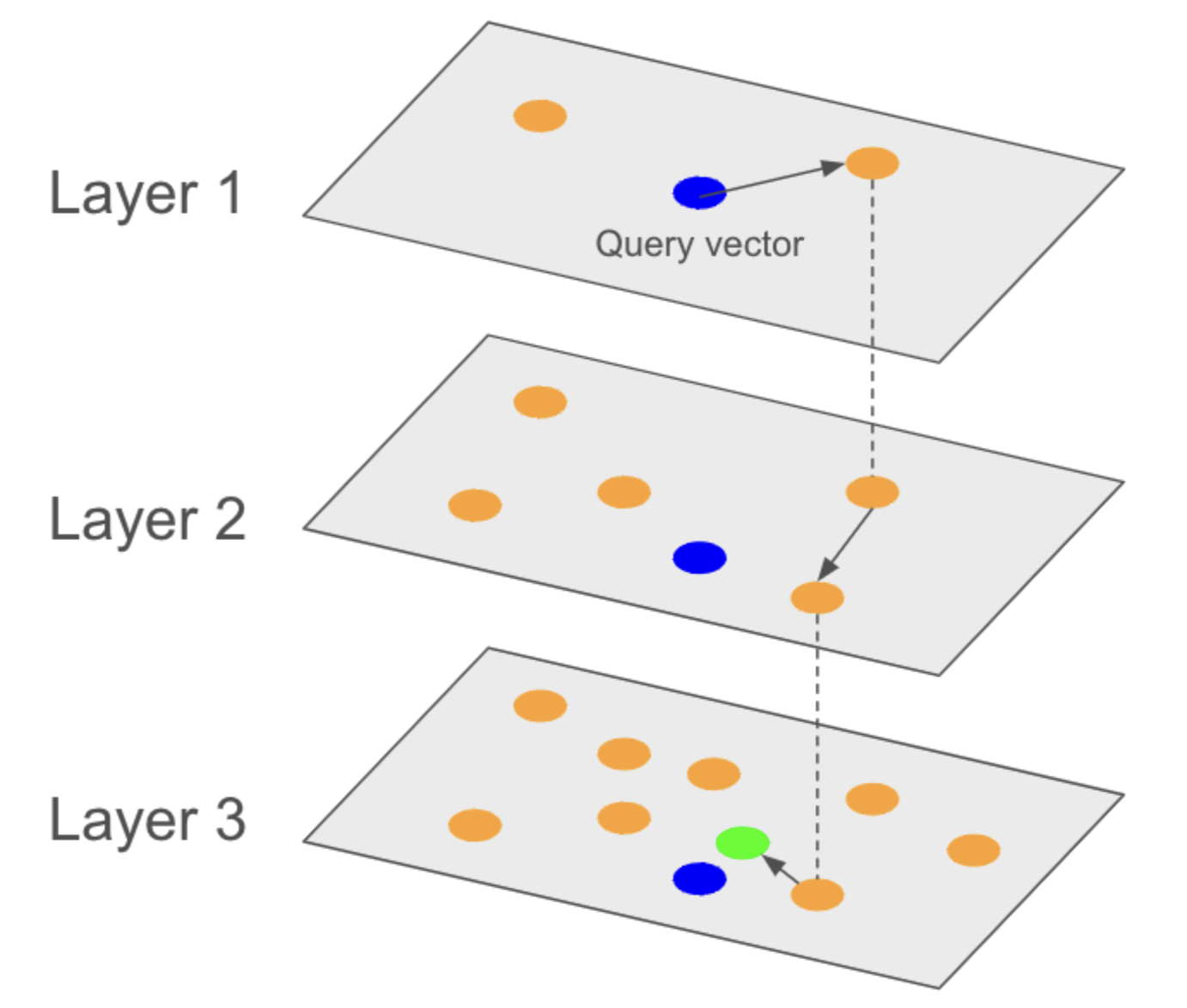
Think of it like zooming in on a map. To find a location, you start large and zoom in further. If you’re trying to find Boston, you hone in on New England. Then, you look around to find the right state. Once you find Massachusetts, you zoom in, and look around to find Boston.
Indexes generally are in-memory for best performance. We can use techniques like binary quantization, scalar quantization, and product quantization to reduce the size of the index to reduce the memory footprint of the index and as a result, reduce costs.
Alternative algorithms for vector search included inverted file indexes (IVF), locally sensitive hashing (LSH), and recently, DiskANN, an algorithm that attempts to allow the vector indexing and search to happen efficiently on disk.
In sum, the main goal of indexing algorithms is to store vectors in a structure that reduces search time while maintaining accuracy.
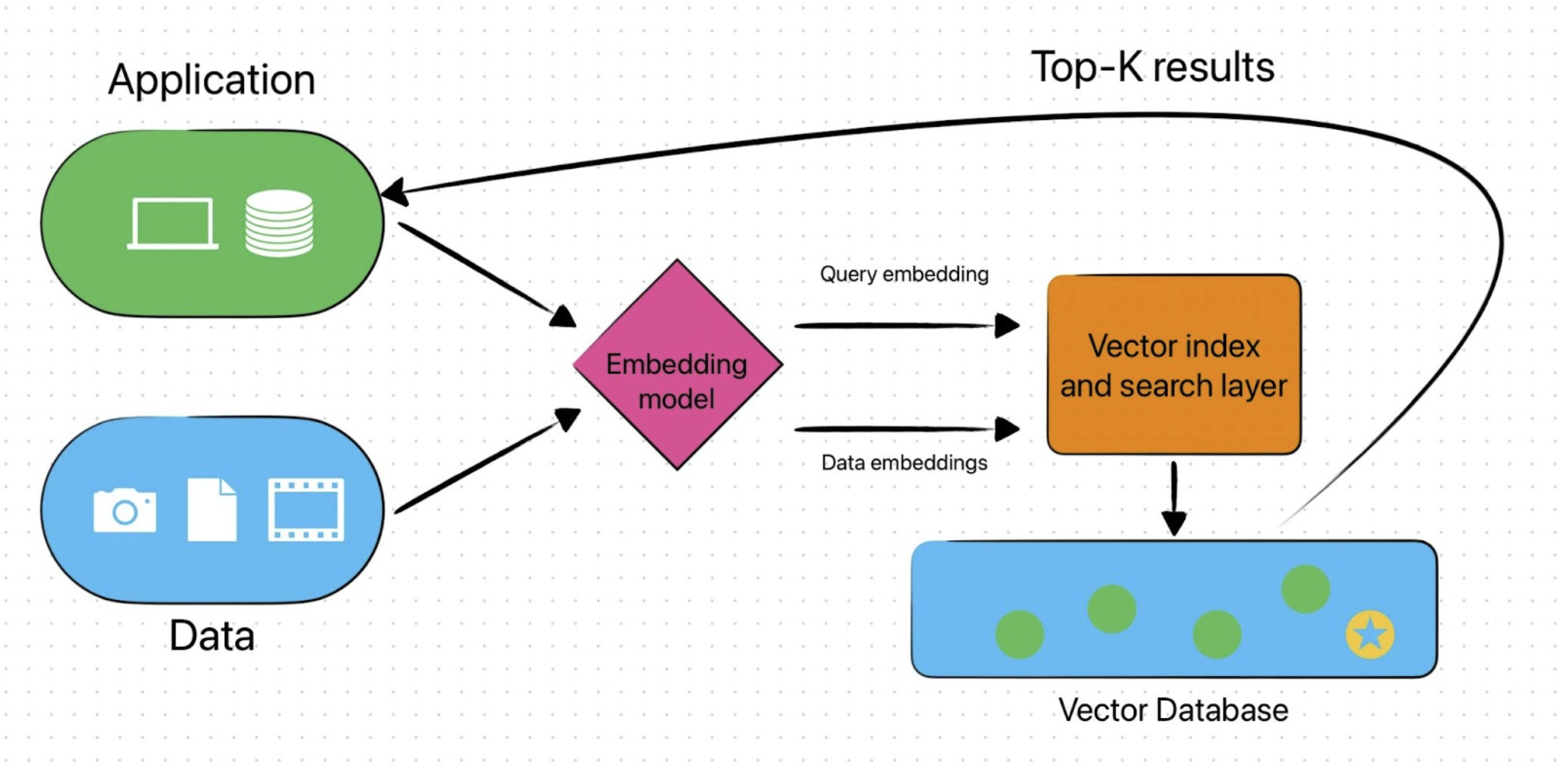
End-to-end diagram for a vector database
Let's put this all together.
Vector databases store objects called vectors, which are numerical representations of unstructured data.
We start by using an embedding model to generate embeddings of all the data we want to store.
Then, we create an index of the vector embeddings to allow for quick retrieval.
When it's time to search, we use the same embedding model from the start to create a vector representation of our search query.
Then, we use our generated vector query to query our vector database. The vector database uses an ANN algorithm to find the closest vectors to our search vector. Those closest vectors represent our answer, which we return to the application.
When to choose a vector database?
To recap, vector databases shine with search over unstructured data. With vectors, we can retrieve information based on the content behind the query, rather than relying solely on exact keyword searches or manually curated features. This is particularly helpful in the following situations.
- Similarity search across data types
- Vector databases are not limited to text; they can enable search across a range of data types, including images, videos, and audio files.
- Better semantic search
- I can query my vector database for “the bald guy who founded the big e-commerce company and lives in Seattle”, and get back Jeff Bezos. Traditional relational databases have a much harder time with this.
- Recommendation systems
- The nature of vectors allows for built-in recommendations. The 10 nearest vectors to your search query are all related or semi-related. Traditional relational databases do not store conceptual proximity.
- Memory storage for AI applications
- AI applications use vector databases to give LLMs access to data they weren’t trained with. What this means is you can provide an LLM with external memory it can access, learn from, and add to.
What about relational databases?
We’ve spent most of this article talking about vector databases. We’ll end by touching on traditional relational databases like Postgres or MySQL, and how they differ from vector databases. Relational databases have been around for decades and excel in many aspects.
- Superior performance for structured content
- CRUD operations are quicker and cheaper with a relational database, full stop.
- Flexibility
- Relational databases are extremely expressive and allow for complex operations across multiple tables and filtering data based on specific criteria.
- Cost
- Relational databases are often lighter on overall cost. This is due to vector databases marking up compute prices and due to the need for vector indexes to be in-memory for better performance.
- Stability and maturity
- Pinecone is one of the more mature vector databases and has been around for about 7 years. Postgres has been around for over 30 years. Production features like replication, fault tolerance, and hybrid search have been battle-tested for years.
Lantern is building support for vectors inside Postgres – spanning vector generation, vector indexing, vector search, and more.