The Write-Ahead Logging (WAL) system is the bedrock of a Postgres system. You rarely think about it in day-to-day operations, but it enables daily used key database features such as fault tolerance, point-in-time recovery streaming replication, backups, and more.
This blog post looks into the underlying plumbing of WAL records - when they are created, what information they contain, and how different database operations affect the kind of WAL records being created.
Why Is There WAL in Postgres?
Postgres employs WAL to achieve two critical objectives: ensuring data integrity and supporting database recovery. Before any changes are made to the data files, Postgres records the change in WAL files. This method guarantees that the database can be restored to a consistent state in the event of a crash by replaying these logs.
The official documentation here provides detailed insights into Postgres's use of WAL to ensure data integrity.
What Would Some Alternatives Be If There Was No WAL?
Without WAL, Postgres would need to rely on other methods to ensure data integrity and support recovery, such as:
- Shadow Paging: This technique involves creating a copy of the database page before modifying it. While this could ensure data integrity and allow for recovery, it is less space-efficient and generally slower than WAL due to the high overhead of copying entire pages.
- Direct Writes: Applying changes directly to the database without any logging mechanism. This approach would significantly speed up write operations but at the cost of losing the ability to recover data after a crash.
Each alternative has performance, complexity, and reliability trade-offs, making WAL a preferred solution in many database systems.
What Affects WAL Size?
Several factors influence the size of WAL files in Postgres:
- Data Inserts and Updates: WAL records must contain all inserted data, in addition to some metadata, so WAL size is proportional to the insert/update rate.
- Indexes: Indexes typically have separate structures which are also WAL protected, so adding indexes increases WAL size.
- Data Type and Size: Large data types generate more WAL data.
- Database Configuration: Parameters like
wal_level,max_wal_size, and others directly impact how WAL is managed and its size. - Changes: Operations such as altering table structures are also logged in WAL, increasing WAL size.
The Postgres configuration documentation provides a thorough guide on adjusting these parameters: Postgres Configuration.
Below, we will explore how data inserts and updates with various indexes enabled the affected amount of generated WAL records.
APIs to Look Into WAL Size
Postgres has a utility function pg_current_wal_lsn, that allows us to examine the database's current position in its write-ahead log. The WAL position is a 64-byte number, and the helper function above returns an abbreviation of it that is enough for our purposes to measure the amount of WAL generated in short periods of time.
Practical Experiments with WAL
Let's start with a simple experiment:
Create an empty table and insert rows
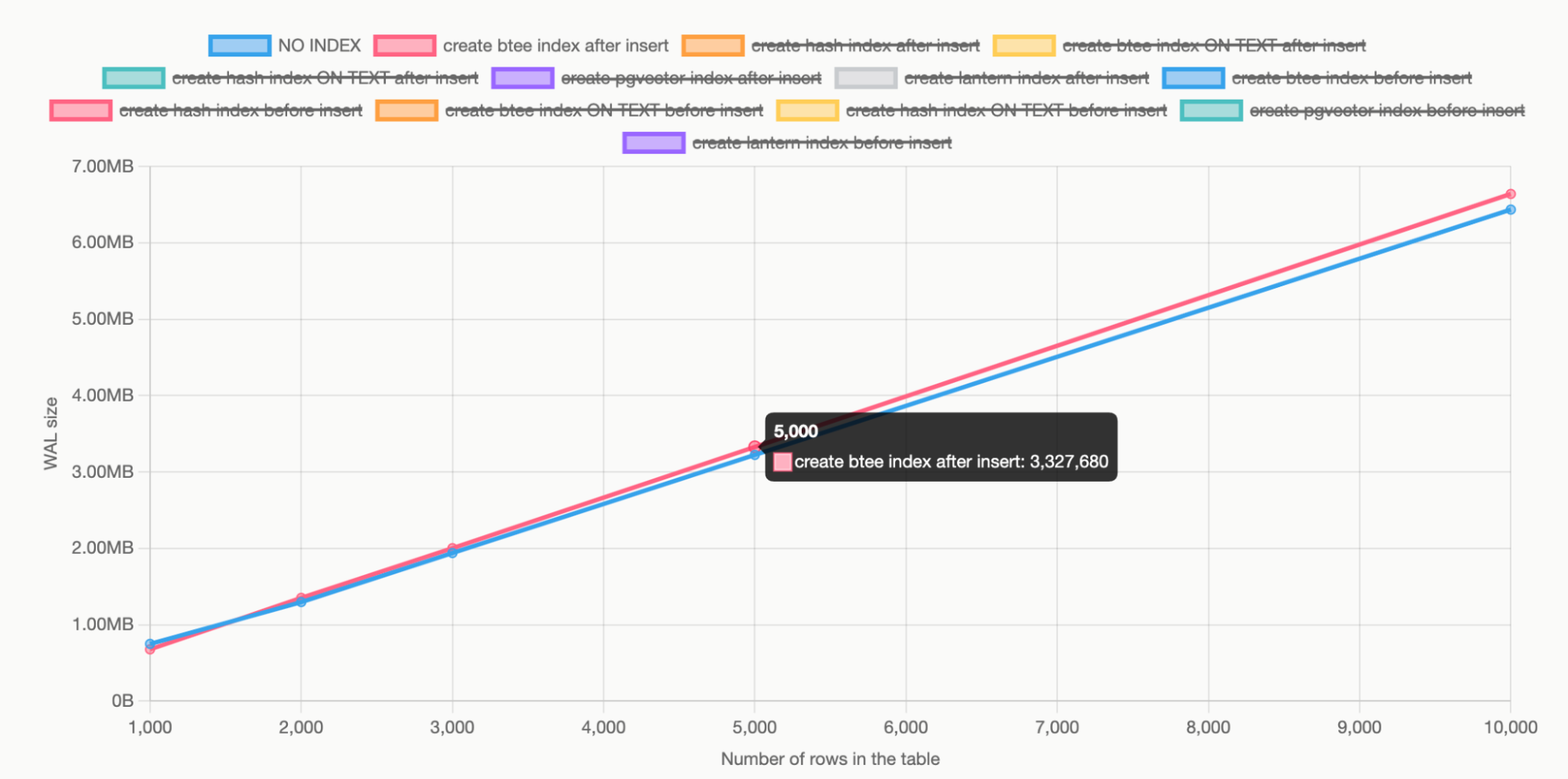
The graph shows that when we have such a table, and we insert 8 byte IDs, 128 dimensional REAL arrays (128 * 4 = 512 bytes), and random MD5 values (32 bytes), we generate 645 bytes of WAL per row.
Considering that just the column lengths add up to 8 + 32 + 512 = 552 bytes, this means that WAL has only a 17% overhead on row data that we insert. We will discuss this overhead in another blog post, but for now, you can get a sneak peek by examining the WAL record types in the appendix.
Create an index on the table after inserting data
WAL Activity: Logs the creation of the index.
Creating a B-Tree index on id is almost unnoticeable on the graph because of the relatively larger table size.
The B-Tree index took 104488 bytes of space for 5k rows. The underlying column it was indexing would take 8 * 5k = 40000 bytes.
Create an index with the table, then insert the data
Let’s run another similar experiment in which we create the index on the table's id column before inserting any data; then, we insert the data. Notice how this causes a noticeably larger amount of WAL to be generated (about 3.5x larger).
We get a larger index because Postgres has to record all individual modifications on the index as we insert more data. This effect is why it is recommended to create indexes after bulk data insertion, not before.For larger data transfers, it is even recommended to drop all indexes, insert data, and recreate indexes.
B-Tree indexes are usually small and this effect usually becomes a bottleneck at 100M to 1B rows. However, the effect is significant, even with smaller tables, for vector indexes, as seen below:
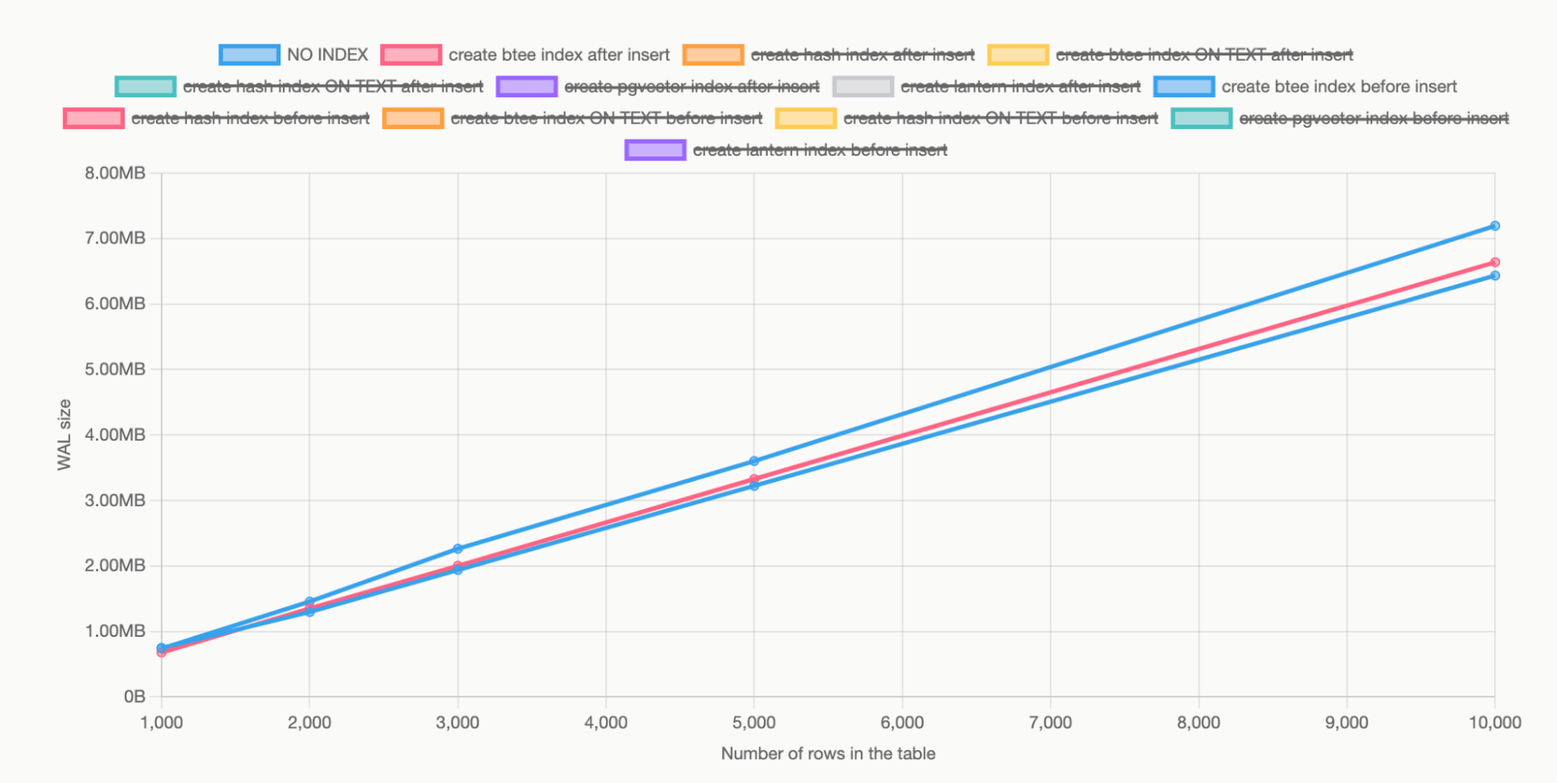
You can use the interactive graphs in the appendix to explore the footprint of other indexes (btree, hash, lantern_hnsw, pgvector hnsw).
Conclusion
The size and management of WAL are critical for maintaining the efficiency and reliability of Postgres databases. Through practical experiments, we can observe how different database operations impact WAL generation, helping database administrators make informed decisions about configuration and optimization.
For more detailed exploration and experiments, the Postgres official documentation is an invaluable resource. Here's a direct link to learn more about WAL configuration and management: WAL Configuration in Postgres.
Appendix
We talked about the aggregate amount of WAL generated in a given experiment setting. But the generated WAL records have different types and serve different purposes such as marking transaction commit status, updating indexes, adding changes to table rows, etc.
In the graphs below you can see the individual record types for each of the experiments in the graph above.