In this article, we'll explore a problem faced when extending traditional Postgres tables with an additional column for embeddings.
We will describe a typical setting for asynchronous embedding generation and will show how table schema design can have a significant impact on storage and performance efficiency.
Typical setup when working with embeddings in Postgres
A common way to extend an existing Postgres deployment with semantic search is to add one or more vector columns corresponding to each column we want to search.
For example, imagine we have a Postgres database containing a table of research paper titles, abstracts and sections that we render in our dashboard and query via keyword search. To additionally support vector search, we would add a vector column to the table to also hold embeddings corresponding to each abstract and sections.
Then, we would continue using our usual pipeline for ingesting data into this table, but would generate embeddings for all rows.
Asynchronous embedding generation
Embedding generation is a time-consuming operation and we likely do not want to slow down the rest of data ingestion pipeline by waiting for embedding generation to complete before we insert rows into the table.
So, it is natural to insert existing data right away and generate embeddings asynchronously in the background. Then, we can insert generated embeddings into the table in batches as they become ready.
This has the added benefit that the rest of our data is available for queries right away, before embeddings are ready.
Table schemas for asynchronous embedding generation
Let’s draw some potential concrete schema options from the example above. One option is to store the abstract and a single embedding column in the same table with corresponding indexes.

Another option is to generate multiple vector embeddings from multiple columns.

When generating embeddings asynchronously, both designs are suboptimal for vector search - they will result in higher disk IO and unnecessary index writes.
Below is a more efficient design:
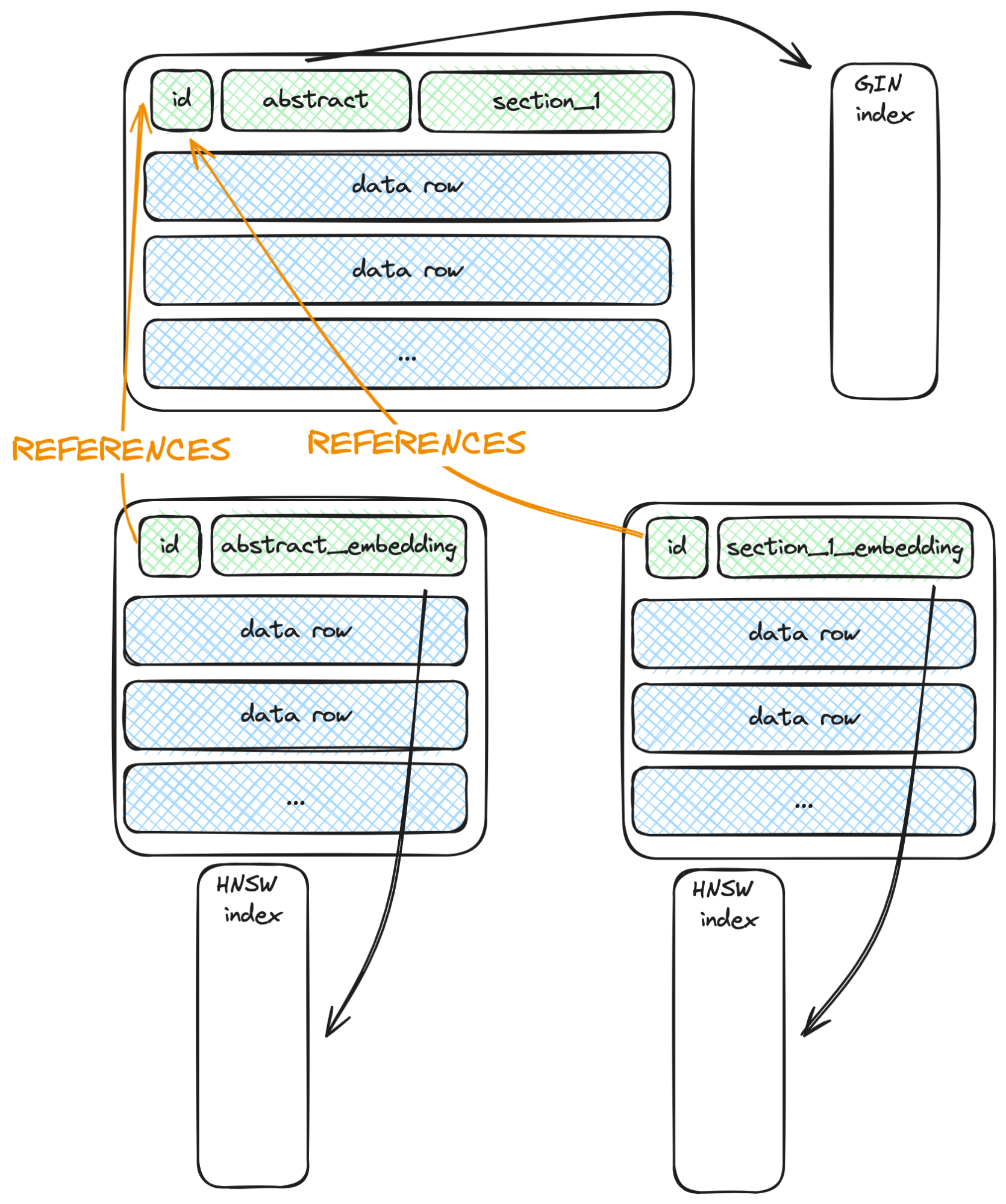
We have moved every indexed and asynchronously updated column into a separate table with a primary key foreign key reference to our data table.
How table schema affects update efficiency
We need some background on how data versioning and indexes work in Postgres to understand the difference.
In Postgres, each row is associated with a unique ID. When a new row is added to the table, its ID is inserted into all relevant table indexes for fast retrieval.
Postgres does not perform in-place updates. Instead, when a row is updated, a new version of the row is inserted into the table with the updated column value(s), and the old row is marked as deleted. For all unchanged columns, the same values are copied over from the previous version of the row. This means that multiple versions of the same row may be alive at any given time.
When a row is updated, the new version of the row must be updated in all table indexes. However, Postgres has an optimization called heap-only tuple (HOT) that allows it to skip index reinsertions if there are no indexes on the updated columns. For example, if section_1 in the table above is updated, the GIN index will not be updated.
This optimization means we do not need to move section_1 to a separate table, like we did with the indexed columns - Due to HOT, updates to section_1 will always be in place and will not update the indexes.
However, this optimization does not work when there is an index on the updated column.
In the original schema design, when we asynchronously generate the embedding, we create a new row, and both GIN and HNSW indexes must be updated. This results in redundant work - only one column was updated, but we did the extra work of reinserting the same thing into another index.
In the latter design, updated rows also generate new row versions on the table and have to be inserted into all indexes of the table. However, crucially, we have only one index per updated column, which is more efficient.
Experimental analysis
We can use WAL measurements as described in the previous blog post to analyze their actual impact.
In one scenario, let’s create a wide table with two indexed vector columns:
CREATE TABLE papers(id bigserial PRIMARY KEY, t1 text, t2 text, v1 real[1536], v2 real[1536]);
CREATE INDEX v1_papers ON papers using hnsw((v1::vector(1536)) vector_cosine_ops) WITH (M=16, ef_construction = 100);
CREATE INDEX v2_papers ON papers using hnsw((v2::vector(1536)) vector_cosine_ops) WITH (M=16, ef_construction = 100);We then insert 10,000 rows into the t1 and t2 columns and asynchronously update the v1 and v2 embeddings. (For the full code, see here.)
In another scenario, let’s instead create separate embedding tables for each embedding column that reference the id of the papers table
CREATE TABLE papers(id bigserial PRIMARY KEY, t1 text, t2 text)
#optionally, create a gin index on one of the text columns
#CREATE INDEX t_gin ON a using gin(to_tsvector(\'english\', t))
CREATE TABLE embeddings1(papers_id bigint PRIMARY KEY REFERENCES papers(id), v real[1536])
CREATE TABLE embeddings2(papers_id bigint PRIMARY KEY REFERENCES papers(id), v real[1536])
# create vector index on the table
CREATE INDEX embeddings1_v ON embeddings1 using hnsw((v::vector(1536)) vector_cosine_ops) WITH (M=16, ef_construction = 100)
CREATE INDEX embeddings2_v ON embeddings2 using hnsw((v::vector(1536)) vector_cosine_ops) WITH (M=16, ef_construction = 100)Inserting 10000 rows into the first table takes ~70% longer and generates 35% more WAL.
Does our proposed design make queries more complex?
No, you can create a view over the underlying tables and leave application queries as is by querying this view instead of the underlying tables.
CREATE VIEW content_and_embeddings AS SELECT a.*, embeddings.v AS v1, embeddings2.v AS v2 FROM a JOIN embeddings ON i = a_id JOIN embeddings2 ON i = embeddings2.a_id;
View "public.content_and_embeddings"
Column | Type | Collation | Nullable | Default
--------+--------+-----------+----------+---------
i | bigint | | |
t | text | | |
t2 | text | | |
v1 | real[] | | |
v2 | real[] | | |Does Lantern help?
With Lantern, the situation is even simpler since we take care of asynchronous embedding generation and keep your embeddings up to date. You only need to interact with your main data table and query the view defined above.