Introduction
We were naturally curious when we saw Pinecone's blog post comparing Postgres and Pinecone.
In their post on Postgres, Pinecone recognizes that Postgres is easy to start with as a vector database, since most developers are familiar with it. However, they argue that Postgres falls short in terms of quality. They describe issues with index size predictability, index creation resource intensity, metadata filtering performance, and cost.
This is a response to Pinecone's blog post, where we show that Postgres outperforms Pinecone in the same benchmarks with a few additional tweaks. We show that with just 20 lines of additional code, Postgres with the pgvector or lantern extension outperforms Pinecone by reaching 90% recall (compared to Pinecone's 60%) with under 200ms p95 latency.
In the original blog post, Pinecone sets up Postgres in a self-hosted environment. Our post can be replicated with a self-hosted setup of Postgres that has the lantern extension installed – see the Jupyter notebooks here. Similar benefits (with some limitations) can be achieved with other hosted Postgres providers and pgvector. Using Lantern Cloud makes some of the steps simpler so we opted for that when running these experiments.
HNSW and Metadata Filtering
Pinecone's blog post points out that a single index over a vector column is not enough to get good filtered search performance. They point out that Postgres does post-filtering out of the box, which is not good enough.
"However, this is only post-filtering, meaning the results are filtered after the search occurs. For all practical purposes, this is unusable, since there’s no guarantee about the number of results that are returned"
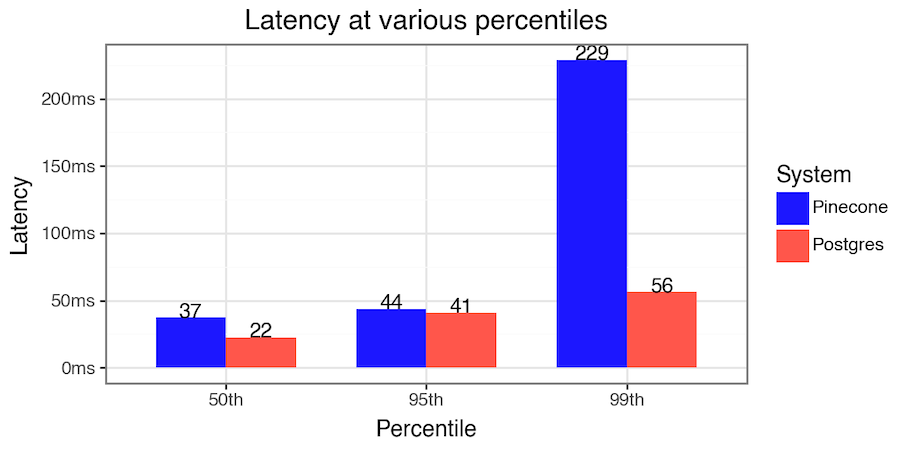
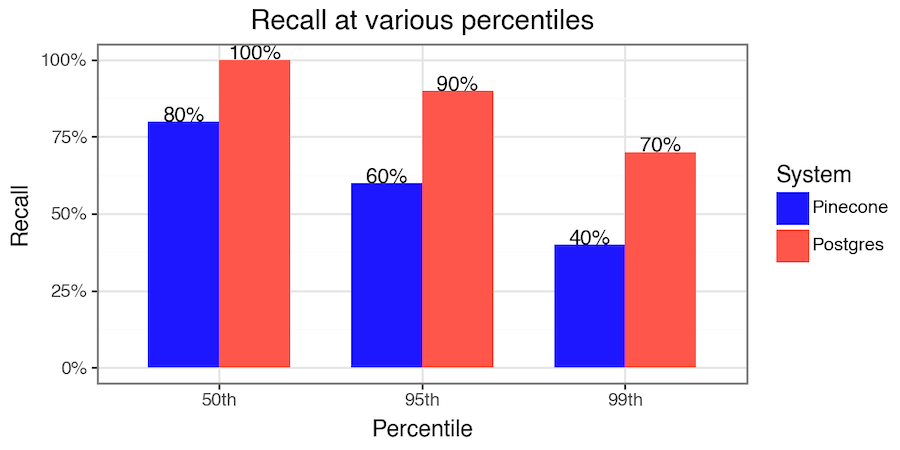
In Postgres, we can explicitly address metadata filtering performance — add 20 lines of code to get 90% p95 recall and 200ms p95 latency. This is in contrast to at most 60% p95 recall that Pinecone achieves on the same dataset (see steps to reproduce and results in the figure later in the post).
To get higher recall and lower latency in Postgres, we convert some of metadata filters into separate vector indexes. The idea is to create a specialized index for each or each group of metadata values so a smaller index can be utilized when doing a metadata search, thereby increasing the chances that only relevant results are returned.
This might sound scary, but with the powers of Postgres and SQL, it is a matter of a couple of queries.
First, let’s look at the metadata tags that we run filters over. Let’s select all the tags that have at least 10K rows tagged by them.
SELECT tag
FROM (
SELECT unnest(metadata_tags) AS tag
FROM yfcc_passages
) AS tags
GROUP BY tag
HAVING COUNT(*) > 10000
ORDER BY COUNT(*) DESCIn the YFCC dataset there are about 1300 such tags.
Then, for each tag we create a separate filtered vector index with a query similar to the one below:
CREATE INDEX CONCURRENTLY IF NOT EXISTS hnsw_filtered_%s
ON yfcc_passages
USING lantern_hnsw(vector)
WHERE metadata_tags @> ARRAY[%s]All the code is available here. Note that we use lantern in our examples but the code has helpers to achieve similar functionality in pgvector as well.
The process of creating all ~1300 indexes completes in 80 minutes on the 10M YFCC dataset with a 32-core server. The job can be completed even more quickly when using Lantern external indexing or a temporarily scaled-up instance from another provider, be it Timescale, Neon, CrunchyData, AWS RDS, GCP Cloud SQL, etc.
And the result?
Postgres achieves over 90% tail recall with metadata filters, while staying fast (<200ms tail latency)! This is a significant improvement over anything currently available via Pinecone.
 å
So 20 lines of "tuning" got us what Pinecone claimed was impractical regardless of tuning:
å
So 20 lines of "tuning" got us what Pinecone claimed was impractical regardless of tuning:
"For any non-trivial workload that requires filtering, it’s impractical to rely on Postgres, regardless of the tuning and setup."
Slow Index Builds
Pinecone points out that Postgres index creation performance degrades very rapidly as soon as the dataset to be indexed no longer fits in the machine’s RAM.
With Lantern Cloud, we address this issue by offloading the index-building process to a separate environment with bottomless RAM and CPUs. With Lantern’s external index creation, you can improve indexing speeds by at least an order of magnitude.
This is available for for pgvector on Lantern Cloud.
Other Postgres cloud providers have addressed the pgvector index creation bottleneck as well. For example, Neon supports seamlessly scaling the size of the Postgres instance to build the initial vector index more quickly and scaling it down afterwards.
In both approaches (Neon and Lantern), index creation is no longer limited by the RAM of our database instance.
Index Size Estimation
Pinecone’s blog post complains that index size is not predictable, and the final index size may be surprisingly larger than the input dataset, so it is hard to plan for the amount of necessary RAM.
We were surprised by this since HNSW index sizes are quite predictable. In fact, we even built a calculator that accurately predicts the amount of RAM an index would need, given its various element quantization and graph density parameters.
Pinecone plots “dataset expansion” - the ratio of the dataset to index - as a measure of index size predictability. They seem to assume that index size should be a function of dataset size in megabytes. This assumption is wrong, as demonstrated in the example below.
Consider two datasets. The first one has 1M 192 dim uint32 datapoints, the second has 250K 768 dim uint32 datapoints. Note that both datasets would weigh about 192 MB.
When building the HNSW graph there is usually a ~100 byte overhead per vector, regardless of the vector dimension (the exact per-vector overhead varies depending on M parameter of HNSW). So, the first dataset would have a ~100MB HNSW graph overhead, while the second one would have 25MB HNSW graph overhead. The fact that HNSW index has two distinct components of vector data and graph is clearly visible from the diagrams in our cost estimation interactive blog post as well.
This would translate into index expansion factors of (25+192) / 192 = 1.13 and (100+192) / 192 = 1.52. The exact same dataset results in HNSW graphs of predictable size but differing expansion factors. So, expansion factor is an inappropriate measure of index size predictability.
We think there is another contributor to artificially inflated pgvector index sizes in pgvector benchmarks by Pinecone: YFCC and MNIST datasets (which result in most expansion in Pinecone’s benchmarks) have int8 single-byte integer vector elements. However, they likely are represented as vector type in pgvector indexes, which has 4 byte floating point elements.
As a result, pgvector indexes get 4x inflated since they store 3 needless bytes for each 1 byte of vector element. pgvector supports halfvec data type which is a 2 byte floating point type and would reduce the artificial inflation. While single byte vector elements are in the works in pgvector, Lantern has support for single byte quantized vector indexes, which we have used for the filtering experiments above.
In sum, index sizes in Postgres are predictable and can be space-efficient. For the chosen YFCC dataset, Lantern indexes are as space-efficient as possible, and pgvector indexes will soon be similarly space-efficient once single precision vector element work gets merged in.
Cost
In the cost section Pinecone concludes that Postgres is more expensive than Pinecone.
Note, however, that Pinecone assumes an average load of 10 requests per minute. Of course Pinecone’s serverless is going to look cheap when you compare it to a setup that can support about 20000 requests per minute with no hardware upgrade.

Above, we plot the monthly cost of various vector databases as a function of query load. We calculate Pinecone cost assuming read-only queries. We calculate the cost of other systems by assuming enough storage for the database and 10x more inserts, and enough RAM for vector indexes (64GB RAM instance, as in Pinecone’s blog post).
As you can see, Pinecone costs a lot when you scale the number of queries per minute. The other systems can sustain the same number of queries per minute with a very cheap instance. In addition, many Postgres cloud providers such as Lantern, Supabase, Neon, Tembo, … have a free tier that could easily fit the kind of load Pinecone assumes.
If cost becomes an issue for larger datasets, Ubicloud offers a 3-5 times cheaper hosted Postgres service. Lantern partners with Ubicloud and offers Lantern Cloud on top of the cheaper Ubicloud base Postgres machines as well, so all Lantern-specific features, such as external indexing, embedding generation, etc., are available on the budget option as well!
To reduce cost even further, you can opt for database instances with much smaller RAM (e.g. 8 GB) that have fast local NVMe SSD block storage. Though this increases the tail latency, the latency still stays under 200ms. For example, for the YFCC experiments above, opting for NVMe SSD drives instead of large RAM to fit the index makes the p95 latency about four times worse - p95 latency increases from 41ms to 172ms. Instances with NVMe storage are available through Lantern on Ubicloud.
Postgres Offers More
Transparency: Pinecone has better defaults and fewer configuration knobs to keep track of. However, these come at the cost of transparency - it is unclear what choices have been made on the user’s behalf and often there is no way to tune them.
E.g., according to Pinecone docs, Pinecone has no guarantee about the number of results that are returned in a metadata-filtered query:
When you use a highly selective metadata filter (i.e., a filter that rejects the vast majority of records in the index), the chosen clusters may not contain enough matching records to satisfy the designated top_k. While similar setup with no guarantees exists trivially from Postgres, unlike Pinecone, Postgres can be configured to provide better support and guarantees due to its transparency.
Inline embedding generation: Since in Postgres data and vectors generated from the data are next to each other (often, as different columns of the same table), it is very easy to manage their lifetime together, generate, and update embeddings. Lantern Cloud even offers an embedding generation service that enables automatic embedding generation and maintenance with a single click in the dashboard.
Supabase - another Postgres cloud provider focused on app developers, has a similar embedding generation offering.
Streaming vector indexes: Though pgvector does not implement it yet, Timescale’s pgvectorscale and Lantern have an optimization that allows streaming a variable number of vectors from a vector index, thereby making it more likely a metadata filter will get hits in post-filtering.
So, using Lantern (likely, also Timescale) improves recall.
Discussion
Didn’t we just demonstrate that Postgres is harder to make performant with all the code we had to write?
No, Postgres enables choice and versatility. Out-of-the-box, these choices are often made with extra SQL statements and functions. Cloud providers such as Lantern make many of these choices behind the scenes to provide a more seamless experience.
It is true that, for example, for metadata filtering, we had to create and maintain additional indexes to make queries performant in Postgres, while Pinecone came with built-in easier-to-use metadata filtering. However, with only 20 lines of additional code we got absolute control over all our metadata values in Postgres, as well as our desired recall and latency.
What happens if, for a particular workload that involves metadata filtering, Pinecone’s recall of 60% is not enough? In Postgres, the question has an easy answer: create the right partial index with an additional line of the CREATE INDEX statement.
How should you choose?
We hope this article gives you some additional relevant context you can evaluate when reading Pinecone’s blog post on Postgres.
Reach out to your Postgres providers and ask them about the features we highlighted in this blog post. If you don’t have a current provider or would rather choose one specialized in GenAI for your GenAI workloads, please keep in touch via [email protected]. We have helped dozens of companies build RAG pipelines powered by Postgres, in Lantern Cloud, in self-hosted Lantern and in other clouds. We would love to help you too.